


Der Weg zur souveränen und zukunftssicheren Datenplattform beginnt mit Open Source
Im Zeitalter datengetriebener Entscheidungen stehen Unternehmen vor der Herausforderung, immer grössere Datenmengen effizient, sicher und flexibel zu verarbeiten. Gleichzeitig entwickeln sich Technologien, Anforderungen und Anwendungsfälle rasant weiter. In diesem dynamischen Umfeld erweisen sich Open-Source-Technologien als der mit Abstand innovativste und nachhaltigste Ansatz für die Datenverarbeitung und -haltung. Open-Source-Lösungen profitieren von einer weltweiten Community aus Entwicklern, Forschern und Anwendern, die kontinuierlich neue Funktionen bereitstellen, Sicherheitslücken schliessen und Best Practices austauschen. Die Innovationsgeschwindigkeit übertrifft die klassischer proprietärer Anbieter bei Weitem, nicht zuletzt, weil Open-Source-Projekte oft direkt an realen Herausforderungen wachsen.
Darüber hinaus schaffen offene Technologien echte Unabhängigkeit. Unternehmen behalten die volle Kontrolle über ihre Daten, Systeme und Weiterentwicklung. Es entstehen weniger Anbieterbindungen, welche die Flexibilität und Innovationskraft langfristig einschränken könnten. Stattdessen lassen sich Open-Source-Komponenten modular einsetzen, kombinieren und exakt auf die eigenen Anforderungen zuschneiden. Ein weiterer entscheidender Vorteil ist, dass offene Technologien nicht nur die Einstiegshürden senken, sondern auch die Chancen, auf dem Arbeitsmarkt geeignete Fachkräfte zu finden, erhöhen. Entwickler und Data Engineers bevorzugen moderne Tools auf Basis offener Standards und vertrauter Sprachen wie Python und SQL, statt sich in schwer zugängliche, proprietäre Technologien einarbeiten zu müssen. Der Aufbau interner Kompetenzen wird dadurch einfacher, schneller und kostengünstiger. Gleichzeitig erhöht sich die Attraktivität des Unternehmens für Fachkräfte, die mit zukunftsorientierten Technologien arbeiten möchten. Auch mit Blick auf Nachhaltigkeit und Skalierbarkeit bietet Open Source klare Vorteile. Die meisten dieser Technologien basieren heute auf offenen Standards, die nahtlose Integration, horizontale Skalierung und den Betrieb in unterschiedlichsten Umgebungen ermöglichen. Nicht zuletzt fördert Open Source eine offene Innovationskultur im Unternehmen selbst. Teams können sich direkt in bestehende Tools einbringen, neue Funktionen entwickeln oder eigene Erweiterungen schaffen, ganz ohne Einschränkungen durch Lizenzmodelle oder geschlossene Schnittstellen.
So offen und zugänglich Open Source auch ist, der produktive Einsatz stellt viele Organisationen vor praktische Hürden. Die Einrichtung und der zuverlässige Betrieb dieser Komponenten erfordern spezifisches technisches Know-how. Noch anspruchsvoller ist es, mehrere Open- Source-Anwendungen so zu orchestrieren, dass sie nahtlos und stabil zusammenspielen. Ohne Erfahrung oder gezielte Unterstützung kann der Aufwand schnell wachsen, gerade beim Aufbau einer vollständig integrierten Datenplattform. Genau hier setzt Open Datastack von ti&m an. Die Plattform vereint moderne und etablierte Open-Source-Technologien zu einer flexiblen und modularen Datenlösung, die durch praxisnahe Zusatzfunktionen echten Mehrwert schafft und kontinuierlich weiterentwickelt wird. So profitieren Unternehmen von den Vorteilen von innovativen Open-Source-Technologien, ohne sich mit den Herausforderungen rund um Betrieb, Integration und Zusammenspiel der einzelnen Komponenten auseinandersetzen zu müssen. Open Datastack nimmt die technische Komplexität ab und sorgt dafür, dass Unternehmen sich ganz auf die Umsetzung ihrer Datenstrategie konzentrieren können.
Offene Technologien, grenzenlose Möglichkeiten
Open Datastack basiert auf etablierten und weit verbreiteten Open-Source-Komponenten wie Apache Superset, Trino, Dagster, Apache Iceberg und Soda Core. Diese leistungsfähigen Bausteine bilden das Fundament für eine modulare und offen gestaltete Plattform, die von ti&m gezielt erweitert wurde: mit benutzerfreundlichen Oberflächen, einem einheitlichen Designsystem sowie einsatzbereiten Funktionen für den produktiven Betrieb. Dabei ist die Offenheit von Open Datastack kein Nebeneffekt, sondern ein zentrales Prinzip. Es gibt keine Abhängigkeiten zu proprietären Technologien, keine intransparenten Systeme und keine Anbieter- oder Plattformbindung. Stattdessen erhalten Organisationen volle Kontrolle über ihre Dashboards und Reports, ihre Datenflüsse und die Möglichkeiten, auf die Weiterentwicklung Einfluss zu nehmen, unabhängig davon, ob sie lokal arbeiten, Lösungen in der Cloud nutzen oder gemischte Umgebungen bevorzugen. Dank der konsequenten Ausrichtung auf offene Standards entsteht ein System, das nicht nur flexibel und anpassbar ist, sondern auch langfristige Investitionssicherheit bietet.
Skalierbar vom ersten Proof of Concept bis zur unternehmensweiten Lösung
Ob als schlanke Visualisierungslösung oder als vollständige Plattform für Datenverarbeitung und Analyse – Open Datastack wächst mit den Anforderungen seiner Nutzer. Die Architektur ist so gestaltet, dass sie kleine Pilotprojekte ebenso unterstützt wie komplexe Datenlandschaften in grossen Unternehmen. Durch die vollständige Kompatibilität mit Containerlösungen wie Docker und Orchestrierungssystemen wie Kubernetes lässt sich Open Datastack problemlos in bestehende Infrastrukturen einfügen. Die Plattform bleibt dabei stets flexibel, zuverlässig und ressourcenschonend, sowohl im lokalen Rechenzentrum als auch in der Cloud. Sie eignet sich für den Einsatz in kleinen, mittleren und grossen Unternehmen gleichermassen. Open Datastack bietet eine zukunftssichere Basis für datengetriebene Innovation, ohne Kompromisse bei Leistungsfähigkeit, Sicherheit, Transparenz oder Datenverantwortung. Dank offener Standards, modularem Aufbau und hoher Erweiterbarkeit können Organisationen jederzeit neue Anwendungsfälle integrieren und ihre Datenstrategie kontinuierlich weiterentwickeln.
Open Datastack bei SUISA
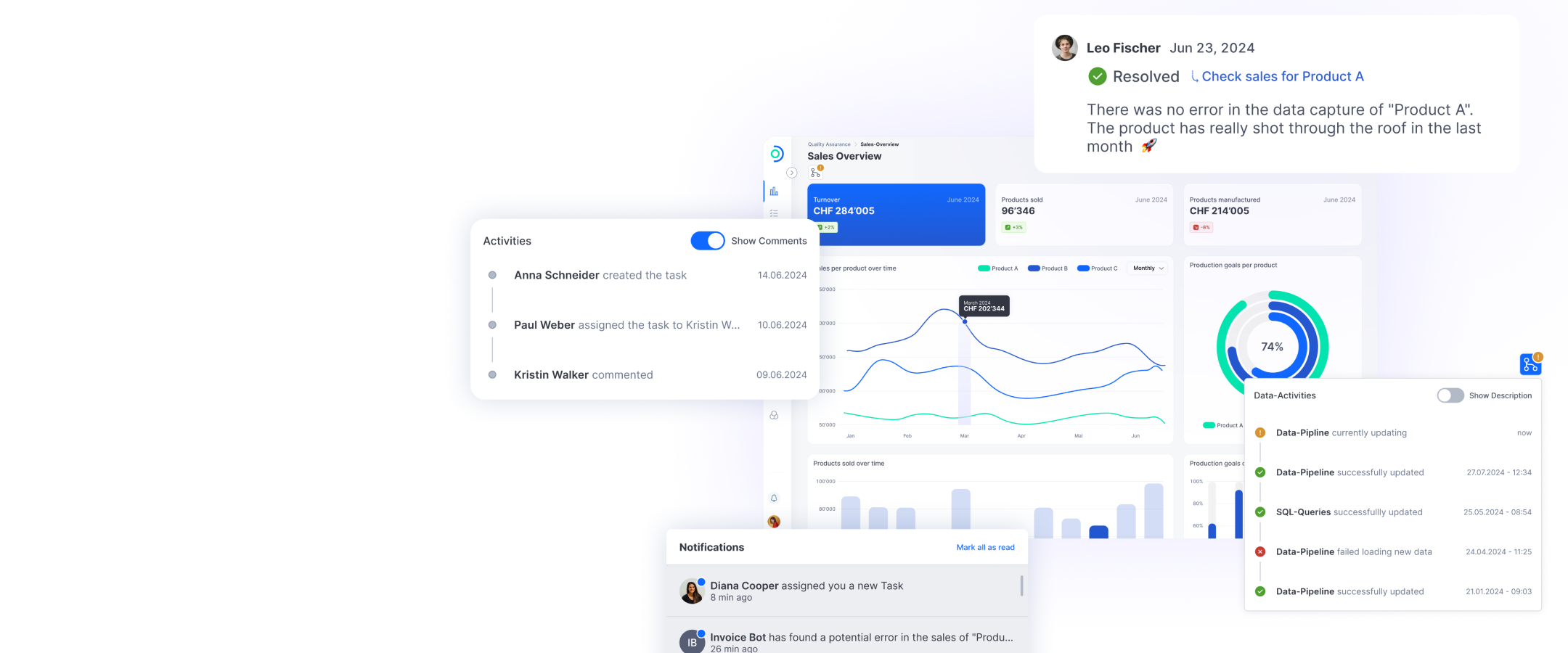
Quality Assurance Reporting für Musikstreaming-Daten
Mint Digital Services – ein Joint Venture der Swiss Collective Management Organization SUISA und der U.S. Music Rights Organization SESAC – vertritt nationale und internationale Künstler gegenüber Streaming-Plattformen wie Spotify, Apple Music, Netflix. Monatlich erhält Mint riesige Datenmengen mit Detailangaben zur Nutzung einzelner Musiktitel, die systematisch analysiert werden müssen, um Unstimmigkeiten oder auffällige Muster zu erkennen. Mint analysiert diese Daten automatisiert, um mögliche Auffälligkeiten in der Nutzung bestimmter Titel zu erkennen. Mithilfe von Open Datastack werden die Resultate zusammen mit weiteren Daten verarbeitet, einzelne Tasks generiert und in Dashboards zusammen mit weiteren Kennzahlen visualisiert. Dadurch können die Mitarbeitenden relevante Anomalien schnell und effizient identifizieren und über den Task-Workflow von Open Datastack nachverfolgen und abarbeiten. Ziel war es, eine skalierbare Lösung zu schaffen, die sowohl eine effiziente Visualisierung grosser Datenmengen als auch die automatisierte Erstellung und Verwaltung von Tasks ermöglicht und zugleich eine technologische Basis für ein künftiges Data Lakehouse bildet. Technisch basiert die Lösung auf Azure Kubernetes Service (AKS). Die Datenaufbereitung erfolgt über Komponenten von Open Datastack sowie über einen angebundenen On-Premises SQL Server, der über ein VPN sicher in die Architektur eingebunden ist.
Zusammenarbeit als Innovationsmotor
Open Datastack ist mehr als die Summe seiner Komponenten. Es verbindet moderne Open-Source-Technologien zu einem leistungsfähigen Framework für kollaborative Business Intelligence. Dashboards sind nicht nur Darstellungen, sondern Ausgangspunkte für Diskussionen, Aufgaben, Entscheidungen. Durch direktes Kommentieren, Nachvollziehbarkeit auf Datenbasis und eingebautes Aufgabenmanagement wird aus Datenvisualisierung ein echter Business-Prozess, welcher transparent, reproduzierbar und teamübergreifend nutzbar ist. Daten haben dann den höchsten Wert, wenn alle Beteiligten gemeinsam mit ihnen arbeiten können. Open Datastack fördert diese Zusammenarbeit. Anomalien, Fragen oder Verbesserungsvorschläge werden nicht länger über separate Kanäle besprochen, sondern direkt im Kontext der Daten sichtbar, diskutierbar und umsetzbar gemacht. Open Datastack ist damit mehr als nur eine technische Lösung zur Visualisierung von Unternehmensdaten. Im Gegensatz zu vielen anderen Plattformen bietet es echten Mehrwert durch nützliche kollaborative Funktionen, wie datenbezogene Aufgaben oder Kommentare und flexible Gestaltung von Dashbards und Navigation entlang realer Unternehmensprozesse. Anstatt sich an starre Abläufe oder vorgegebene Strukturen anpassen zu müssen, können Unternehmen ihre Datenumgebung mit Open Datastack prozessorientiert, teamübergreifend und dynamisch gestalten.
Die Grundlage für vertrauenswürdige KI im Unternehmen
Immer mehr Daten werden für den Zugriff durch KI-Anwendungen verfügbar gemacht. Chatbots und AI Agents greifen dabei auf operative Unternehmensdaten zurück, um Fragen zu beantworten oder Aufgaben zu lösen. Da diese Daten in modernen Datenplattformen wie Open Datastack in der Regel zentralisiert und harmonisiert vorliegen, eignen sich solche Plattformen hervorragend als vertrauenswürdige Bezugsquelle für KI-Anwendungen. Durch die vorgelagerte Datenaufbereitung kann sichergestellt werden, dass die zugrunde liegende Datenqualität einen bestimmten Standard erfüllt, anders als bei direktem Zugriff auf operative Systeme, bei dem Rohdaten häufig unvollständig, widersprüchlich oder uneinheitlich aufgebaut sind. Das Model Context Protocol (MCP) gilt als zukünftiger Standard für den datenbasierten Einsatz von KI-Anwendungen und setzt sich zunehmend gegenüber der Retrieval- Augmented Generation (RAG) durch. MCP ist ein offenes Protokoll, das standardisierte Möglichkeiten bietet, um KI-Modelle mit unterschiedlichen Datenquellen und Werkzeugen zu verbinden. Im Gegensatz zu RAG ermöglicht MCP einen kontrollierten, nachvollziehbaren und transparenten Datenzugriff für verschiedene KI-Anwendungen. Damit schafft MCP die Grundlage für vertrauenswürdige und steuerbare KI-Systeme, während RAG oft ungezielt arbeitet und die Herkunft der verwendeten Informationen schwer nachvollziehbar ist. Durch den im Open Datastack integrierten MCP-Server lässt sich der Zugriff verschiedener KI-Anwendungen auf die Informationen innerhalb der Datenplattform sehr genau steuern. Für jede Anwendung kann festgelegt werden, auf welche Daten in welchem Umfang zugegriffen werden darf. Zudem werden alle Abfragen in Form von SQL-Anfragen, die durch die verschiedenen Anwendungen gestellt werden, protokolliert. Diese Protokolle können beispielsweise zur Erkennung von Unregelmässigkeiten oder zur Definition neuer Anforderungen weiterverwendet werden. Damit behalten Unternehmen jederzeit die Kontrolle über die genutzten Daten und erkennen, welche Informationen besonders relevant sind. Auf dieser Grundlage lassen sich gezielt neue Anforderungen für Auswertungen oder Dashboards ableiten. Mit Open Datastack können Unternehmen KI-Anwendungen Zugriff auf ihre zentrale Datenplattform gewähren, ohne Kompromisse bei Zugriffskontrolle, Datenqualität und Sicherheit eingehen zu müssen. Damit sind sie bestens gerüstet für das Zeitalter von Chatbots und AI Agents.
Offenheit als strategischer Vorteil
In einer Zeit, in der Datenstrategien über Innovationsfähigkeit und Wettbewerbsstärke entscheiden, liefert Open Datastack die passende Grundlage: offen, skalierbar und auf modernen Open-Source-Technologien aufgebaut. Es ist die Plattform für alle, die mehr wollen als ein Dashboard und bereit sind, zusammen mit ti&m aus Daten echten Mehrwert zu schaffen.
ti&m Special «Swiss Software und KI»
KI trifft Swiss made: Innovation aus der Schweiz
Special, Digital Banking
Metaverse: Virtuelle Realität oder digitaler Traum?
Metaverse // Einige Firmen haben in den letzten Monaten erste Metaverse-Projekte lanciert, so auch ti&m: Die Kunstwerke unseres jährlichen Kunstprojekts art@work waren dieses Mal nicht nur physisch an den Vernissagen zu sehen, sondern auch bei einem virtuellen Rundgang mittels VR-Brillen in der Virtual Reality zu bestaunen. Zudem haben wir für jedes gekaufte Werk ein Non-Fungible Token (NFT) ausgestellt. Grund genug einmal nachzufragen, was andere Branchen so treiben.
Joséphine Chamoulaud, Cécile Moser - 28.03.2023
Innovation, Special
Von gesundheitsfördernden Armbändern und digitalen Lifestyle-Coaches
Singapore-ETH Centre // 2010 wurde das Singapore-ETH Centre (SEC) von der ETH Zürich und der Nationalen Forschungsstiftung Singapurs (NRF) als Teil des NRF-Campus für Forschungs-exzellenz und technologisches Unternehmertum (CREATE) gegründet. Als einziges Forschungszentrum der ETH Zürich ausserhalb der Schweiz stärkt das Zentrum die Forschungs-kapazität der ETH Zürich, um nachhaltige Lösungen für globale Herausforde- rungen in der Schweiz, Singapur und den umliegenden Regionen zu entwickeln.
Dr. Thomas Meyer - 24.08.2023