


The path to a sovereign and future-proof data platform starts with open source
In the age of data-driven decisions, companies face the challenge of processing increasingly large amounts of data efficiently, securely, and flexibly. At the same time, technologies, requirements, and use cases are evolving rapidly. In this dynamic environment, opensource technologies are proving to be by far the most innovative and sustainable approach to data processing and management. Open-source solutions benefit from a global community of developers, researchers, and users who are constantly providing new functions, closing security gaps, and sharing best practices. The speed of innovation far exceeds that of traditional proprietary providers, not least because open-source projects often grow directly in response to real challenges.
In addition, open technologies create genuine independence. Companies retain full control over their data, systems, and further development. There are fewer vendor lock-ins that could limit flexibility and innovation in the long term. Instead, open-source components can be used modularly, combined, and tailored precisely to specific requirements. Another key advantage is that open technologies not only lower the barriers to entry, but also increase the chances of finding suitable specialists on the labor market. Developers and data engineers prefer modern tools based on open standards and familiar languages such as Python and SQL instead of having to learn proprietary technologies that are difficult to get to grips with. This makes it easier, faster, and more cost-effective to build up internal expertise. At the same time, the company becomes more attractive to specialists who want to work with future-oriented technologies. Open source also offers clear advantages in terms of sustainability and scalability. Today, most of these technologies are based on open standards that enable seamless integration, horizontal scaling, and operation in a wide variety of environments. Last but not least, open source promotes an open culture of innovation within the company itself. Teams can contribute directly to existing tools, develop new features, or create their own extensions, without being restricted by licensing models or closed interfaces.
However, as open and accessible as open source is, its productive use poses practical hurdles for many organizations. Setting up and reliably operating these components requires specific technical expertise. And getting multiple open-source applications to work together seamlessly and smoothly is even more challenging. Without experience or targeted support, the workload can grow quickly, especially when setting up a fully integrated data platform. This is exactly where Open Datastack from ti&m comes in. The platform combines modern and established open-source technologies to create a flexible and modular data solution that is continuously being developed further and delivers real added value thanks to additional functions tailored to practical needs. This allows companies to reap the benefits of innovative open-source technologies without having to deal with the challenges associated with operating, integrating, and coordinating the individual components. Open Datastack removes the technical complexity and ensures that companies can concentrate fully on implementing their data strategy.
Open technologies, limitless possibilities
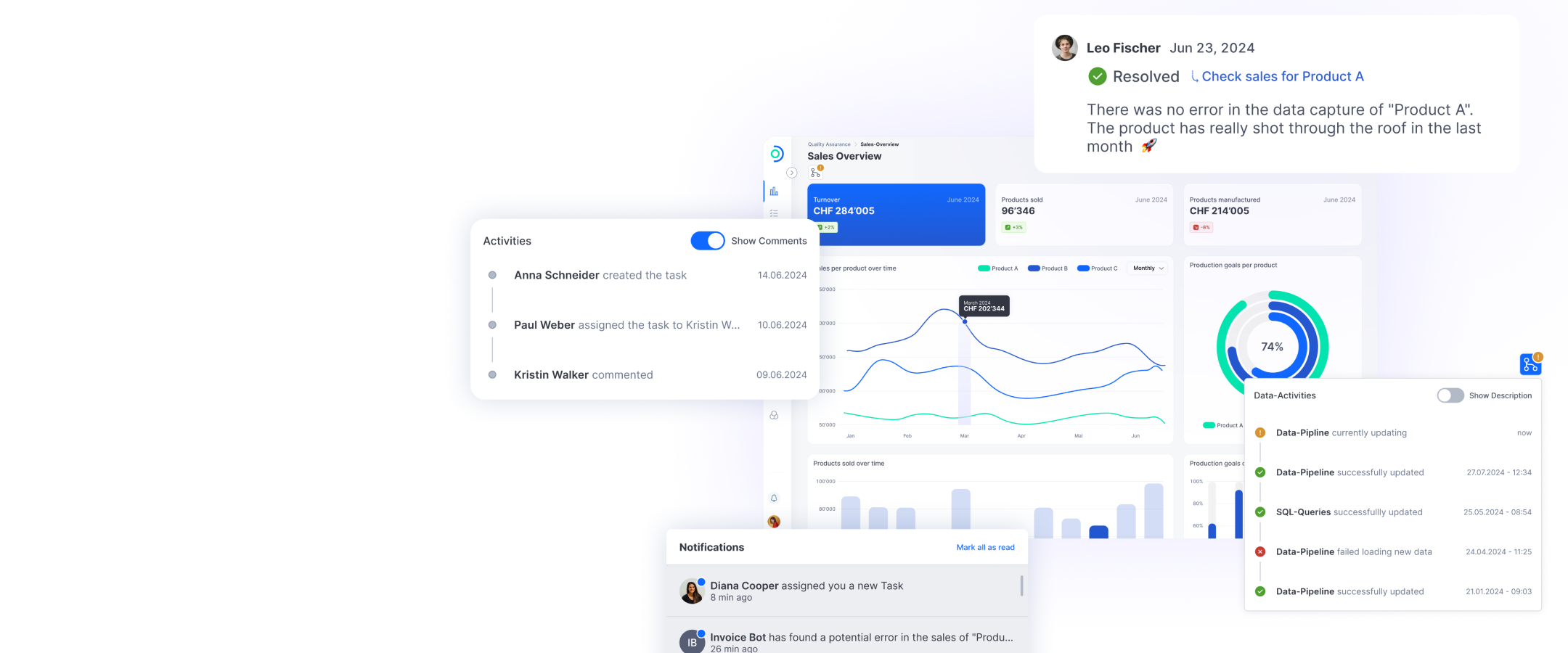
Open Datastack is based on established and widely used open-source components such as Apache Superset, Trino, Dagster, Apache Iceberg, and Soda Core. These powerful building blocks form the foundation for a Open Datastack // Flexible, scalable, collaborative, and open: Open Datastack combines all the advantages of open source, such as innovative strength and independence, on a central platform. For companies that want to lay the foundations for a modern, sustainable data future today. ti&m Special “Swiss software and AI” 2025 29 modular and open platform that has been specifically expanded by ti&m with user-friendly interfaces, a uniform design system, and ready-to-use functions for productive operation. Moreover, the openness of Open Datastack is not a side effect; it is a core principle. There are no dependencies on proprietary technologies, no non-transparent systems, and no vendor or platform lock-in. Instead, organizations gain full control over their dashboards and reports, their data flows, and the possibilities for influencing further development, regardless of whether they work locally, use solutions in the cloud or prefer mixed environments. Thanks to the consistent focus on open standards, the result is a system that is not only flexible and adaptable, but also offers long-term investment security.
Scalable from the first proof of concept to a company-wide solution
Whether as a lean visualization solution or as a complete platform for data processing and analysis, Open Datastack grows with the requirements of its users. The architecture is designed to support everything from small pilot projects to complex data landscapes in large companies. Thanks to its full compatibility with container solutions such as Docker and orchestration systems such as Kubernetes, Open Datastack can be easily integrated into existing infrastructures. The platform always remains flexible, reliable and resourceefficient, both in the local data center and in the cloud. It is equally suitable for use in small, medium-sized and large companies. Open Datastack offers a futureproof foundation for data-driven innovation, without compromising on performance, security, transparency, or data responsibility. Thanks to open standards, modular design, and high expandability, organizations can integrate new use cases at any time and continuously develop their data strategy.
Open Datastack at SUISA
Quality assurance reporting for music streaming data
Mint Digital Services — a joint venture between the Swiss collective management organization SUISA and US music rights organization SESAC — represents national and international artists in dealings with streaming platforms such as Spotify, Apple Music, and Netflix. Every month, Mint receives huge amounts of data with detailed information on the use of individual music tracks. This data has to be systematically analyzed to detect discrepancies or unusual patterns. Mint analyzes this data automatically to identify any anomalies in the use of certain tracks. With the help of Open Datastack, the results are processed together with other data, and individual tasks are generated and visualized in dashboards together with other key figures. This enables employees to quickly and efficiently identify relevant anomalies and to track and resolve them via the Open Datastack task workflow. The aim was to create a scalable solution that enables both the efficient visualization of large amounts of data and the automated creation and management of tasks, while also forming a technological basis for a future data lakehouse. Technically, the solution is based on Azure Kubernetes Service (AKS). Data is prepared using Open Datastack components and a connected on-premises SQL server, which is securely integrated into the architecture via a VPN.
Collaboration as a driver of innovation
Open Datastack is more than the sum of its parts. It combines modern open-source technologies to create a powerful framework for collaborative business intelligence. Dashboards are not just representations, but starting points for discussions, tasks, and decisions. Direct commenting, data-based traceability, and built-in task management turn data visualization into a genuine business process that is transparent, reproducible, and can be used across teams. Data has the highest value when everyone involved can work with it together. Open Datastack promotes this collaboration. Anomalies, questions, or suggestions for improvement are no longer discussed via separate channels, but become visible, open to discussion, and implementable directly in the context of the data. Open Datastack is therefore more than just a technical solution for visualizing company data. Unlike many other platforms, it offers real added value through useful collaborative features such as data-related tasks or comments and flexible design of dashboards and navigation based on real company processes. Instead of having to adapt to rigid processes or predefined structures, companies can use Open Datastack to design their data environment in a process-oriented, cross-team, and dynamic way.
The basis for trustworthy AI in companies
More and more data is being made available for access by AI applications. Chatbots and AI agents use operational company data to answer questions or solve tasks. Since modern data platforms such as Open Datastack typically store this data in a centralized and harmonized format, they are ideal as a trustworthy source for AI applications. Upstream data preparation can ensure that the underlying data quality meets a certain standard, unlike direct access to operational systems, where raw data is often incomplete, contradictory, or inconsistently structured.
The Model Context Protocol (MCP) is regarded as the future standard for the data-based use of AI applications and is increasingly gaining ground over Retrieval Augmented Generation (RAG). MCP is an open protocol that offers standardized options for connecting AI models with different data sources and tools. In contrast to RAG, MCP enables controlled, traceable, and transparent data access for various AI applications. MCP thus lays the foundation for trustworthy and controllable AI systems, whereas RAG often works in an untargeted manner and the origin of the information used is difficult to trace.
The MCP server integrated in Open Datastack allows very precise control of access to the information within the data platform by various AI applications. For each application, it is possible to specify which data may be accessed and to what extent. In addition, all queries in the form of SQL requests made by the various applications are logged. These logs can be used, for example, to detect irregularities or to define new requirements. This allows companies to retain control over the data used at all times and identify which information is particularly relevant. On this basis, users can derive targeted new requirements for evaluations or dashboards. With Open Datastack, companies can grant AI applications access to their central data platform without having to compromise on access control, data quality, or security. This means they are ideally equipped for the age of chatbots and AI agents.
Openness as a strategic advantage
In an age where data strategies determine innovative ability and competitive strength, Open Datastack provides the ideal foundation: open, scalable, and built on modern open-source technologies. It is the platform for anyone who wants more than just a dashboard and is ready to work with ti&m to create real added value from data.
ti&m Special “Swiss software and AI 2025”
AI meets Swiss made: Innovation from Switzerland
Special, E-Government
Agile procurement and procurement of agile projects
Thomas Molitor - Dec 29, 2021
Special, AI
How artificial intelligence impacts digital marketing
Digital marketing // Big data and artificial intelligence have been key elements in marketing for years now. But easy access to tools like ChatGPT and improvements in the latest version of Google Analytics are opening up new opportunities that marketers can benefit from.
- Apr 23, 2024
Special, AI-and-Open-Source
Digital sovereignty: How much progress have European cloud providers made?
Steffen Pfahler - Mar 2, 2026