


How to use AI to make the most of company data
AI assistants // Intelligent chatbots like the ti&m AI Assistants combine company data with the intelligence of ChatGPT or Google Bard. This gives companies a chatbot that can support employees with many different tasks, and simplify and improve customer communication.
Today, modern companies and organizations are large, decentralized knowledge factories. But where is this knowledge actually stored? A lot of it is in the minds of the employees — we hope. And even more is stored on various servers and databases. Decentralized storage makes it difficult to retrieve the right knowledge at the touch of a button. This is because you first have to laboriously search through various databases and scan pages of hits for the information you need, and then interpret this information correctly to draw the right conclusions. With the exponential growth of knowledge and data, it’s becoming increasingly difficult to make internal expertise available to all employees in an efficient way. Technology partners such as ti&m provide solutions that break down information silos and make granular knowledge available to all employees and customers at all times. Solutions like the AI Assistant generate eloquent answers to complex questions based on internal company data, and make them available via a user-friendly interface. Employees and customers can then implement these to enhance their productivity.
Data pools and embeddings
Large language models like GPT are largely trained with publicly accessible data such as scientific publications, entries on knowledge sites such as Wikipedia etc. and have billions – in the case of GPT-4 it is 1800 billion – of parameters. ChatGPT generates its response to a prompt based on the data set used to train it, and it’s also possible to add context to a prompt. For example, a prompt can request that a text be shortened to five sentences, if you send the text as context. If you link com pany data to ChatGPT using an AI Assistant, each prompt is given company-specific context. Companies have a lot of data, and the pool is constantly being added to through customer communications such as phone calls, webchats and emails, or through product enhancements. This data is stored in text or video format on the website or in countless documents on the intranet, servers or other databases. So how does the AI Assistant choose the relevant documents that are automatically added to the prompt? Embeddings. Embeddings are vectors that represent the meaning of a specific section of text. The company’s in-house documents and data are converted into embeddings and stored in a vector database. If the user asks a question, this is also converted into an embedding and the chatbot searches for the relevant documents in the database. These documents are then passed along with the question to ChatGPT, which generates a coherent answer based on them. This makes all your company’s knowledge accessible to all employees and customers. The AI Assistant isn’t limited to answering questions — it can also create a PowerPoint presentation tailored to a specific target group based on the answer, send the answer automatically in an email, or be linked up to other applications such as JIRA, Slack or GitHub. To increase transparency, it can also indicate the sources on which the answer is based.
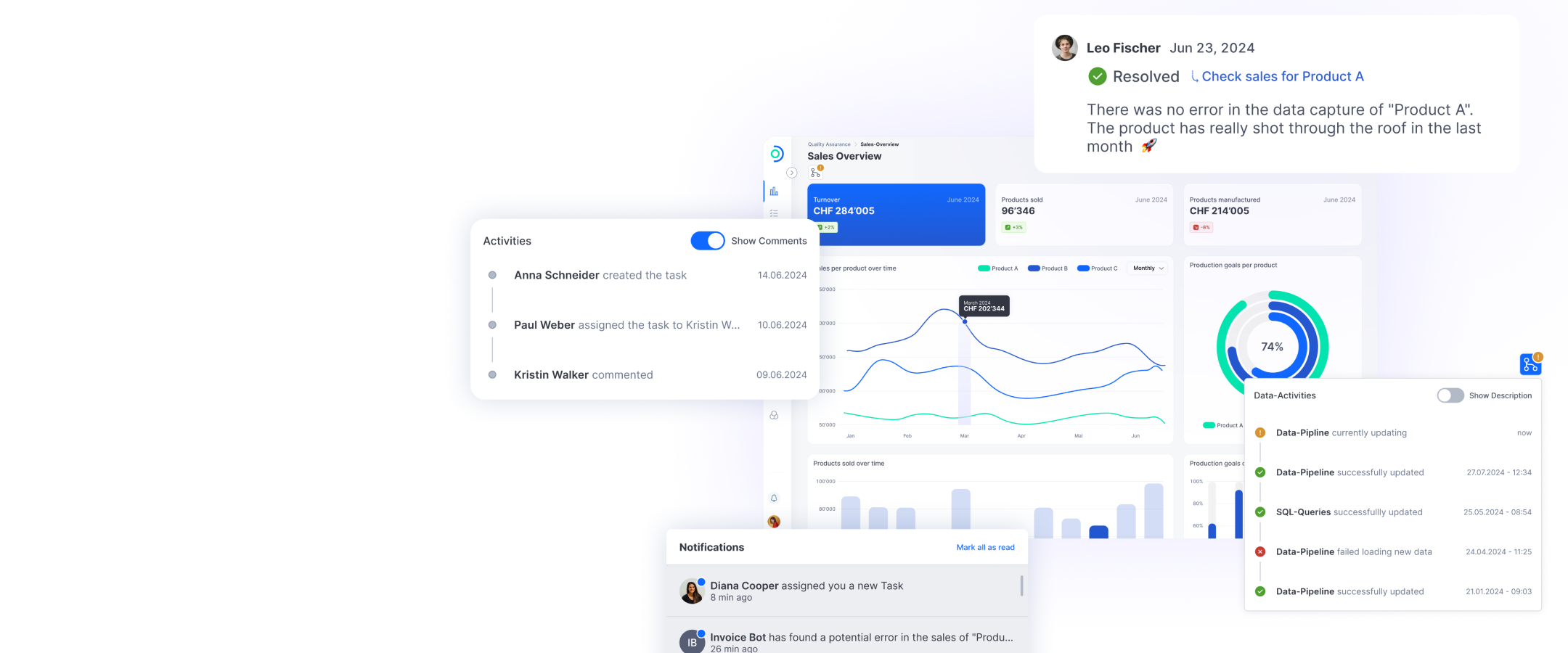
How the ti&m AI Assistant works
Step 1: Define data pool and index data
Step 2: Search indexing
Step 3: Identify relevant information
Step 4: GPT-4 generates the answer
Lowering hurdles for LLM projects using ChatGPT
With the launch of solutions based on large language models, such as ChatGPT, it’s not just AI that’s become part of everyday life. The launch makes LLM-based AI projects much more cost-effective. In the past, machine learning and AI solutions were often challenging, and some required a lot of effort. But now LLMs such as the various versions of GPT are opening up a completely new approach. Developers can use existing LLMs to create AI solutions for companies in any sector, making it comparatively inexpensive — instead of having to collect data and train models, integrating company data is often sufficient. The AI Assistant helps employees to use existing data more efficiently and in a more targeted manner, automate processes, build closer customer relationships or develop new products and services, while customers receive an intelligent bot to respond to their concerns.
How our customers use AI
Automated personal check
Better baking thanks to image recognition
Usage forecasting and anomaly detection


Special, Innovation
New approaches in quality assurance
Innovative testing // An ever-increasing number of people are joining the digital world – and demands and requirements for digital solutions are growing just as rapidly. The upshot for quality assurance is that innovative technologies and methods are a must to meet these requirements.
Larissa Baiter, Timo Tomasini - Jul 3, 2023
Swiss-Software-AI, Special
Digital sovereignty: Why Switzerland must act now
Philip Dieringer - Oct 13, 2025
Technology, Special
Digitalisation calls for Agile strategy processes
- Mar 1, 2019