


Wie Sie Firmendaten dank KI optimal nutzen
AI Assistants // Intelligente Chatbots wie der ti&m AI Assistant verbinden Firmendaten mit der Intelligenz von ChatGPT oder Google Bard. Firmen erhalten damit einen Chatbot, der Mitarbeitende bei vielen Aufgaben unterstützt und die Kundenkommunikation vereinfacht und verbessert.
Moderne Firmen und Organisationen sind heute grosse, dezentralisierte Wissensfabriken. Aber wo ist dieses Wissen eigentlich abgespeichert? Vieles ist (hoffentlich) in den Köpfen der Mitarbeitenden. Und noch mehr liegt auf verschiedenen Servern und Datenbanken. Diese dezentrale Aufbewahrung macht es schwierig, das passende Wissen auf Knopfdruck abzurufen. Denn erst müssen mühsam verschiedene Datenbanken durchsucht, die seitenlangen Treffer nach den benötigten Information gescannt und die gefundenen Informationen am Ende noch richtig interpretiert und daraus die richtigen Schlüsse gezogen werden. Mit dem exponentiellen Wachstum von Wissen und Daten wird es zunehmend schwierig, allen Mitarbeitenden das interne Know-how effizient zur Verfügung zu stellen. Technologiepartner wie ti&m liefern Lösungen, die nicht nur Informationssilos aufbrechen und das Wissen granular allen Mitarbeitenden und Kundinnen und Kunden jederzeit verfügbar machen. Lösungen wie der AI Assistant generieren auf Basis von firmeninternen Daten sprachlich ansprechende Antworten auf komplexe Fragen und stellen diese in einem nutzerfreundlichen Interface so zur Verfügung, dass Mitarbeitende und Kundinnen und Kunden einen produktiven Nutzen daraus ziehen.
Datenpool und Embeddings
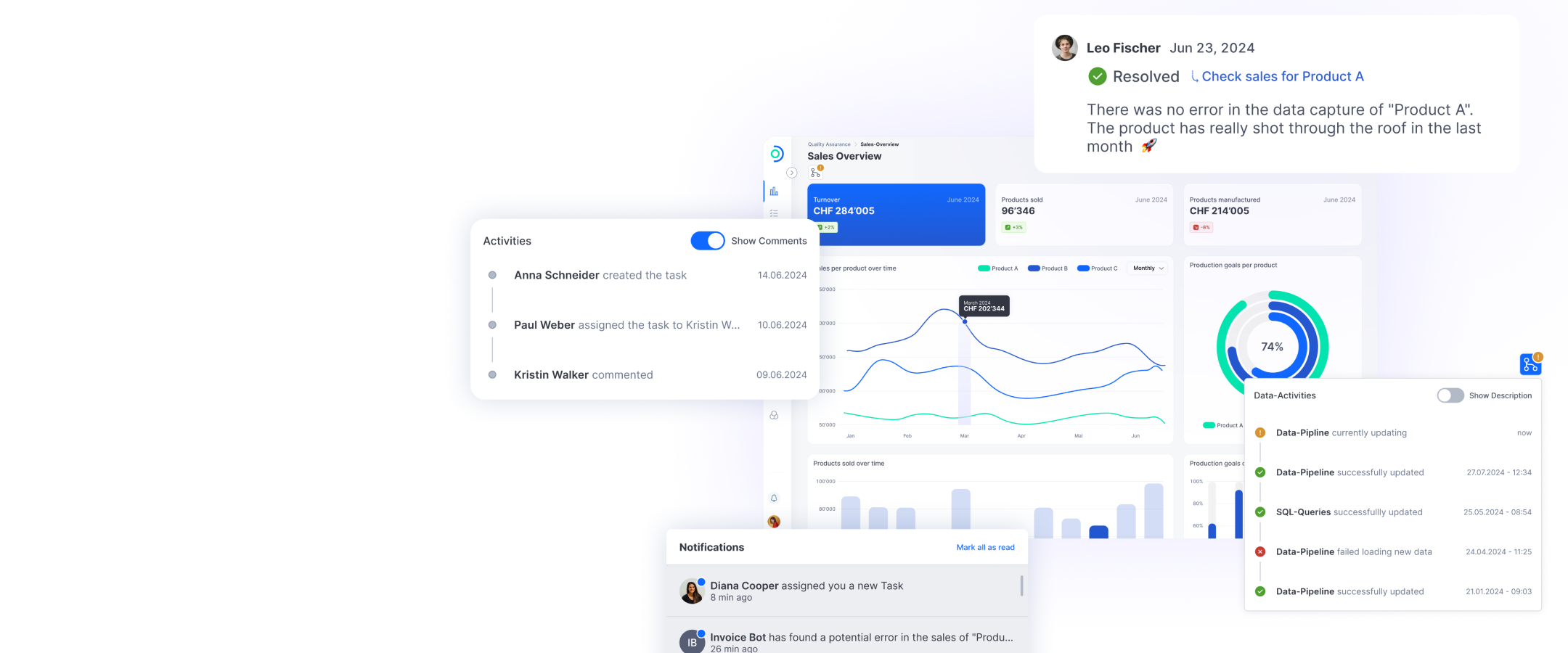
Large Language Models wie GPT werden zum grössten Teil mit öffentlich zugänglichen Daten wie wissenschaftliche Publikationen, Einträge auf Wissensseiten wie Wikipedia usw. trainiert und haben Milliarden – bei GPT-4 sind es 1’800 Milliarden – von Parametern. Bei einem Prompt generiert ChatGPT die Antwort zum einen auf der Grundlage des trainierten Datensatzes, zum anderen kann einem Prompt auch ein Kontext mitgegeben werden. Bspw. kann in einem Prompt verlangt werden, diesen Text auf fünf Sätze zu kürzen, wobei der Text als Kontext mitgeschickt werden muss. Verbindet man die Firmendaten durch einen AI Assistant mit ChatGPT, wird jedem Prompt fi rmenspezifischer Kontext mitgegeben. Firmen besitzen viele Daten und laufend kommen durch die Kundenkommunikation wie Telefonate, Chat oder E-Mails oder durch Produkterweiterungen neue dazu. Diese Daten sind in Text- oder Videoformat auf der Webseite oder in zahllosen Dokumenten auf dem Intranet, auf Servern oder in anderen Datenbanken abgelegt. Wie wählt der AI Assistant also die relevanten Dokumente aus, die automatisch dem jeweiligen Prompt mitgegeben werden? Mit Embeddings. Embeddings sind Vektoren, die den Sinn eines Textabschnitts repräsentieren. Die eigenen, firmenspezifi schen Dokumente und Daten werden in Embeddings umgewandelt und in einer Vektorendatenbank gespeichert. Stellt die Nutzerin oder der Nutzer eine Frage, wird diese ebenfalls in ein Embedding umgewandelt und der Chatbot sucht in der Datenbank die relevanten Dokumente heraus. Diese Dokumente werden zusammen mit der Frage ChatGPT übergeben, der basierend darauf eine kohärente Antwort generiert. Das gesamte Wissen ihrer Firma wird so für alle Mitarbeitenden und Kunden zugänglich. Der AI Assistant kann dabei nicht nur eine Frage beantworten, sondern aus der Antwort eine auf eine bestimmte Zielgruppe zugeschnittene Powerpoint-Präsentation erstellen, die Antwort automatisch in einem Mail verschicken oder an andere Applikationen wie JIRA, Slack oder Github angebunden werden. Um die Transparenz zu erhöhen, können die Quellen angegeben werden, auf denen die Antwort basiert.
So funktioniert der ti&m AI Assistant
Schritt 1: Datenpool festlegen und Daten indexieren
Schritt 2: Suchindexierung
Schritt 3: Relevante Informationen identifizieren
Schritt 4: GPT-4 generiert die Antwort
Tiefere Hürden für LLM-Projekte dank ChatGPT
Mit der Lancierung von Large-Language-Models-basierten Lösungen wie ChatGPT ist nicht nur KI im Alltag angekommen. Die Lancierung macht LLM-basierte KI-Projekte auf einen Schlag viel kostengünstiger. Denn waren Lösungen im Bereich Machine Learning und KI bisher oft anspruchsvoll und teilweise mit hohen Aufwänden verbunden, ermöglichen LLMs wie die verschiedenen Versionen von GPT ein völlig neues Vorgehen. Entwicklerinnen und Entwickler können auf bestehende LLMs zurückgreifen und so für Firmen aus allen Branchen kosteneffektiv KI-Lösungen bereitstellen. Denn anstatt selbst Daten zu sammeln und Modelle zu trainieren, reicht es, mit Retrieval Augmented Generation (RAG) Unternehmensdaten zu integrieren und mithilfe von Prompt Engineering in einem sogenannten Zero-Shot Learning die richtigen Fragen zu stellen. Der AI Assistant unterstützt Mitarbeitende, vorhandene Dateneffizienter und zielgerichteter zu nutzen, Prozesse zu automatisieren, Kundenbeziehungen zu intensivieren oder neue Produkte und Dienstleistungen zu entwickeln, während Kundinnen und Kunden einen intelligenten Bot für ihre Anliegen erhalten.
Wie unsere Kunden KI nutzen
Automatisierte Personenprüfung
Besser Backen dank Image Recognition
Nutzungsprognose und Erkennung von Anomalien


Special, Future of Work
Der Arbeitsplatz – neu definiert
ti&m places // Die Pandemie, aber auch die Arbeit mit wechselnden Partnern, das Bedürfnis nach geografischer Unabhängigkeit und nicht zuletzt die hohen Kosten für Bürofläche und Infrastruktur haben den Trend zu neuen Arbeitsformen nachhaltig beschleunigt. Nun sind Tools gefragt, um neue hybride Arbeitsplatzstrategien einfach umzusetzen.
- 21.11.2022
Special, Swiss-Software-AI
KMU-Kredite: unterschiedliche Wahrnehmung von Banken und KMU
Thomas Fischer - 05.09.2025
Special, E-Government
Agile Beschaffung und Beschaffung agiler Projekte
Thomas Molitor - 29.12.2021