


Large Language Models: a Game Changer
Artificial intelligence // At the beginning of May, Geoffrey Hinton was the latest veteran AI researcher to warn against the potential of “new” AI. But it was already clear that a short-term hype cycle doesn’t adequately explain current developments.
What happened? For a few years now, it has been clear that human brilliance isn’t the best basis for improving AI. What makes a difference is massive data scaling, more computing power, and larger models. Richard S. Sutton shared this insight in 2019 in his high-profile essay The Bitter Lesson. And this viewpoint proved true in 2022 and 2023. Using enormous computing power, large quantities of data, and flawless engineering, OpenAI created GPT-3.5/4, a model that astounded people around the world. Accessible to everyone as ChatGPT, this generalized model makes work easier in many different professions.
And this is just the start. It’s clear that the next generation of models will be able to process more than text: images, camera feeds, audio files, and even robot sensor information. The big players in the field of AI are following suit with similar models. Google made its PaLM 2 model available via API at the end of May. And there are already open source models that perform at a similar level to GPT-4. The development of these large language models (LLMs) like GPT-4 isn’t just exciting for end users. These models are also changing day-to-day work for the machine learning engineers at ti&m. While projects in machine learning and AI have often been demanding and required a lot of effort, LLMs open up a completely new approach. Take one example: a customer in the insurance industry wants to build software that automatically directs incoming claims to the correct department. Three years ago, this would have been an extensive project that included:
- Procuring or generating sufficient data for training and testing an ML model.
- Training and testing various model architectures.
- Integrating the trained model in a conventional piece of software.
In many cases, this process required multiple iterations to achieve the necessary quality. It was hard work, but it was the only way to solve complex problems using AI. The arrival of LLMs is creating new options for projects like these. Rather than needing to collect data and train models, it is now often enough to ask the right questions with the help of prompt engineering in a zeroshot learning setup. Let’s look at two project examples:
Project 1 “Analyzing customer communication with LLMs”
Almost every larger retail company collects large volumes of data via customer communication such as phone calls, emails, and chats. Analyzing these data can deliver clear added value: Are customers satisfied with the products? If not: Why is this? What are customers’ key needs right now? How many conversations address the topic of XY and how often?
These days, it takes little effort to answer these questions and others. The first step is transcribing phone conversations. AI models that (more or less reliably) translate speech into text have been around for many years. But for niche languages such as Swiss German, the quality was often inadequate or needed a lot of work. With Modern AI models such as Whisper (open source; developed by OpenAI) you can now transcribe conversations in Swiss German into written German text of a very high quality. Even relatively difficult dialects are easily possible without any specific training. Once the oral communication has been put into writing, analyzing it is very easy with GPT-4. But the right prompts have to be developed depending on each use case. When it comes to a straightforward summary of a conversation, a simple prompt suffices, such as “Please summarize the following conversation in three brief, concise sentences.” The prompts become somewhat longer for other use cases. Additional prompt engineering tricks also make it possible to ensure that the model’s answers are a true representation and as error-free as possible.
From a technical standpoint, a project of this type is an integration project first and foremost:
- How can we connect a company’s internal phone system to speech-to-text models such as Whisper?
- Where and for how long can we securely store transcribed conversations of a sensitive nature?
- How can we integrate GPT4 (for example, via Azure)?
- How can we process large numbers of conversations efficiently, perhaps almost in real time, during peak periods?
Technology partners like ti&m can support integration projects like these thanks to their interdisciplinary teams of AI, software, and DevOps experts.
Project 2 “AI assistant: a ChatGPT for company data”
Our second specific example of a project for LLMs is a close approximation of the original ChatGPT: What if a company could offer its customers a truly smart AI assistant that can deliver precise answers on products and services? What if the assistant had access to customerspecific information that would allow it to answer complex questions like, “How much money did I spend on products X and Y last year?” This is possible by combining smart LLMs such as GPT4 with company data (see architecture overview). The first step consists of indexing all the relevant company data. It doesn’t matter whether the data are stored in a folder as separate documents such as PDFs and Word files, or whether they are structured data in a database. The next step is storing the indexed data in a search index, which often takes the form of “embeddings”. Let’s say a user now asks a specific question such as “How much does service XY cost in the year XZ”? In this case, the first step is using retriever or questionanswering models to search the documents that might contain an answer to the question. There might be five or even 50 documents. What matters is that a large number of irrelevant documents can be eliminated very quickly. The few remaining documents are now sent to GPT4 together with the question and any other information. GPT4 reads the sent documents, combines the relevant facts, and writes a coherent answer referring to the source documents. The AI assistant then passes the answer and the sources to the user. They can choose the corresponding medium — a chatbot on the website, an integration in MS Teams or WhatsApp, or even an automatic answer via email — depending on their preferences.
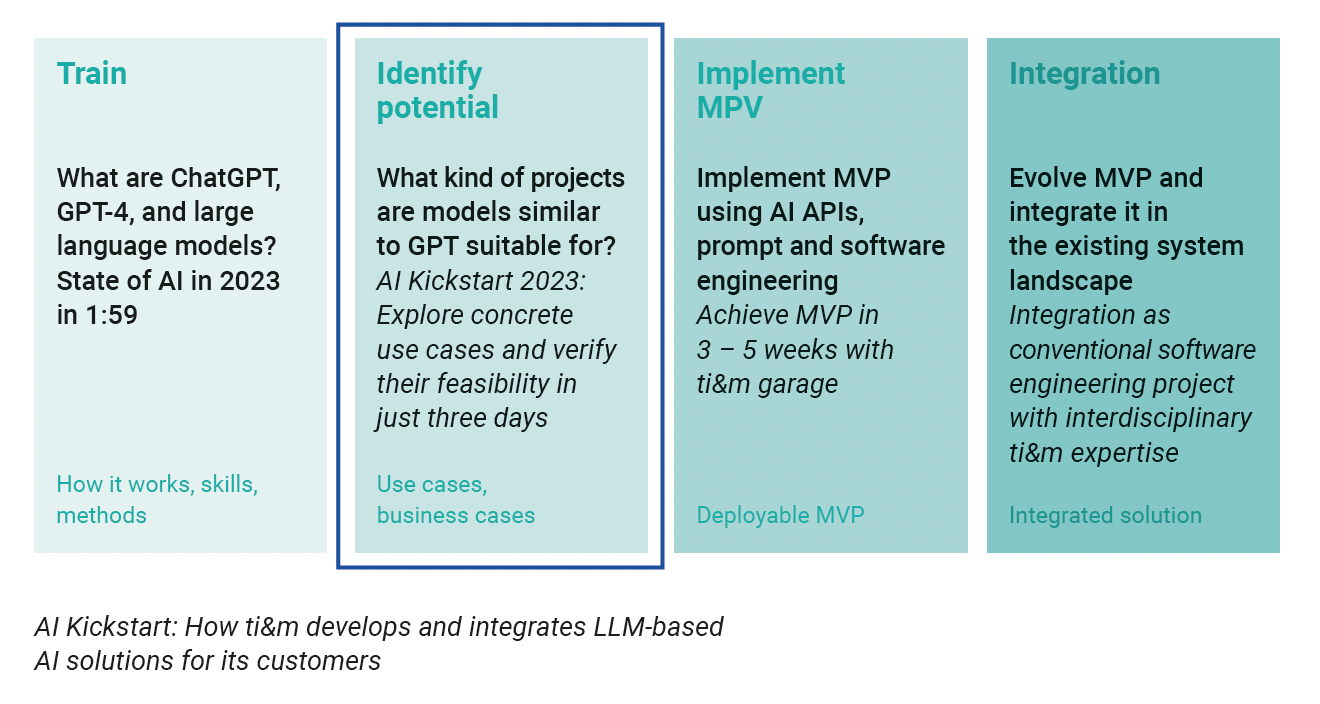
AI Kickstart with ti&m
The possibilities that AI offers are constantly growing, and the potential applications for different areas and sectors are growing along with them. For every technological development, it is important to remember: You don’t have to do everything all at once. What is certain is that setting up work processes and developing new business models is more efficient thanks to AI. To gether with a strong technology partner, companies should identify these opportunities and implement use cases that deliver clear added value, fast. And this is exactly what ti&m offers with AI Kickstart: During this threeday workshop, our experts offer an introduction to the AI technology and identify specific use cases together with our customers. Following the workshop, our teams implement the initial version of a minimal viable product in three to five weeks. This is then integrated in the customer’s existing system landscape. Thanks to this approach, ti&m supports its customers in the stepbystep process of adapting AI to their business.


Special
“Disruption isn’t off the menu. It’s just taking a bit longer.”
Markus Gygax - Mar 1, 2019
Special, Swiss-Software-AI
The path to a sovereign and future-proof data platform starts with open source
Silvan Meier - Sep 22, 2025
Special, Future of Work
Working in the cloud – the challenges for data protection
Data protection // Sooner or later, every organization or business needs to address the question of digital transformation and therefore get to grips with the cloud. A number of aspects must be carefully considered first in order to avoid any legal pitfalls.
Ursula Sury - Oct 24, 2022