



Schluss mit «Works on my Machine»: MLOps «Golden Path» Blueprint für regulierte Industrien
Wir starten ins Jahr 2026. Die Zeiten, in denen Data-Science-Teams ihre Modelle via USB-Stick oder als ZIP-File an die IT-Abteilung übergeben haben, sind endgültig vorbei. Die Tooling-Landschaft hat sich in den letzten Jahren massiv konsolidiert. Wir diskutieren heute nicht mehr darüber, ob wir Container brauchen, sondern wie wir die Supply Chain unserer KI-Modelle so absichern, dass sie nicht nur performant sind, sondern auch den steigenden Governance-Anforderungen standhalten.
Dennoch sehen wir in unseren Projekten bei ti&m oft ein Paradoxon: Während die Algorithmen immer komplexer werden (Transformers, Agentic Workflows), hinkt das Engineering hinterher. Da werden Notebooks in Produktion «gehackt» oder Pipelines gebaut, die so fragil sind, dass sich niemand traut, die requirements.txt anzufassen.
Für Unternehmen, die ML nicht als Spielwiese, sondern als geschäftskritischen Treiber sehen, gibt es nur eine Lösung: Platform Engineering. Wir müssen einen «Golden Path» bauen – eine standardisierte, hochautomatisierte Strasse in die Produktion.
In diesem Beitrag zeigen wir, wie ein solcher Blueprint aussieht, den wir für Kunden in regulierten Industrien (Banken, Versicherungen) heute architektieren. Wir schauen unter die Haube von GitOps, OCI-Artefakten, modernem Dependency Management mit uv und Observability.
Das Mindset: Compliance by Design und Schweizer Pragmatismus
Bevor wir Code anschauen, ein Wort zur Architektur. In einem regulierten Umfeld ist «Agilität» kein Freifahrtschein für Chaos.
Das Thema Regulierung – Stichwort EU AI Act – ist auch für Schweizer Unternehmen zentral. Zwar sind wir politisch unabhängig, aber wirtschaftlich stark verflochten. Sobald ein Schweizer Unternehmen KI-Services im EU-Raum anbietet, greift die Regulierung (Extraterritorialität). Zudem orientiert sich auch der Schweizer Gesetzgeber an internationalen Standards.
Für uns Technikerinnen und Techniker ist dabei gar nicht der juristische Text entscheidend, sondern die technische Implikation. Vor allem zwei Aspekte sind für MLOps-Plattformen relevant:
Technical Documentation & Record-Keeping (Art. 11 & 12): Wir müssen lückenlos beweisen können, wie ein Modell entstanden ist. Wer hat es trainiert? Auf welchen Daten? Mit welchen Parametern?
Accuracy, Robustness & Cybersecurity (Art. 15): Ein Modell darf nicht manipulierbar sein und muss gegen Angriffe geschützt werden.
Manuelle Schritte sind hier der Feind. Unser Ziel bei ti&m ist es daher, eine Plattform zu bauen, bei der Compliance das automatische Resultat ist, nicht ein Formular, das man am Ende ausfüllt.
Unsere Architekturprinzipien für 2026:
1. GitOps First: Die Single Source of Truth ist immer Git. Das garantiert die lückenlose Historie (Audit Trail).
2. Immutable Artifacts: Ein Modell ist ein binäres Artefakt, das einmal gebaut und dann unverändert durch die Stages (Dev, Test, Prod) promoted wird.
3. Separation of Concerns: Data Scientists liefern den Inhalt (Code + Parameter), die Plattform liefert den Rahmen (Security, Skalierung, Monitoring).
Deep Dive 1: Reproduzierbarkeit beginnt lokal (Die uv-Revolution)
Blicken wir kurz zurück. Dependency Management in Python war lange ein Albtraum. pip, poetry, conda, pipenv – das Auflösen von Abhängigkeiten dauerte oft Minuten.
2025 hat sich uv als De-facto-Standard durchgesetzt, und 2026 ist es aus modernen Stacks nicht mehr wegzudenken. Warum ist das für MLOps entscheidend? Weil Governance mit Reproduzierbarkeit steht und fällt.
Wenn ein Data Scientist lokal ein Modell entwickelt, muss die Umgebung bit-genau der Trainingsumgebung in der Cloud entsprechen. Früher führte «Works on my Machine» zu stundenlanger Fehlersuche in der CI-Pipeline.
Mit uv können wir Environments in Millisekunden erstellen und synchronisieren.
Ein Blick in die Praxis:
Statt einer losen requirements.txt nutzen wir strikte Lockfiles (uv.lock), die plattformübergreifend funktionieren.
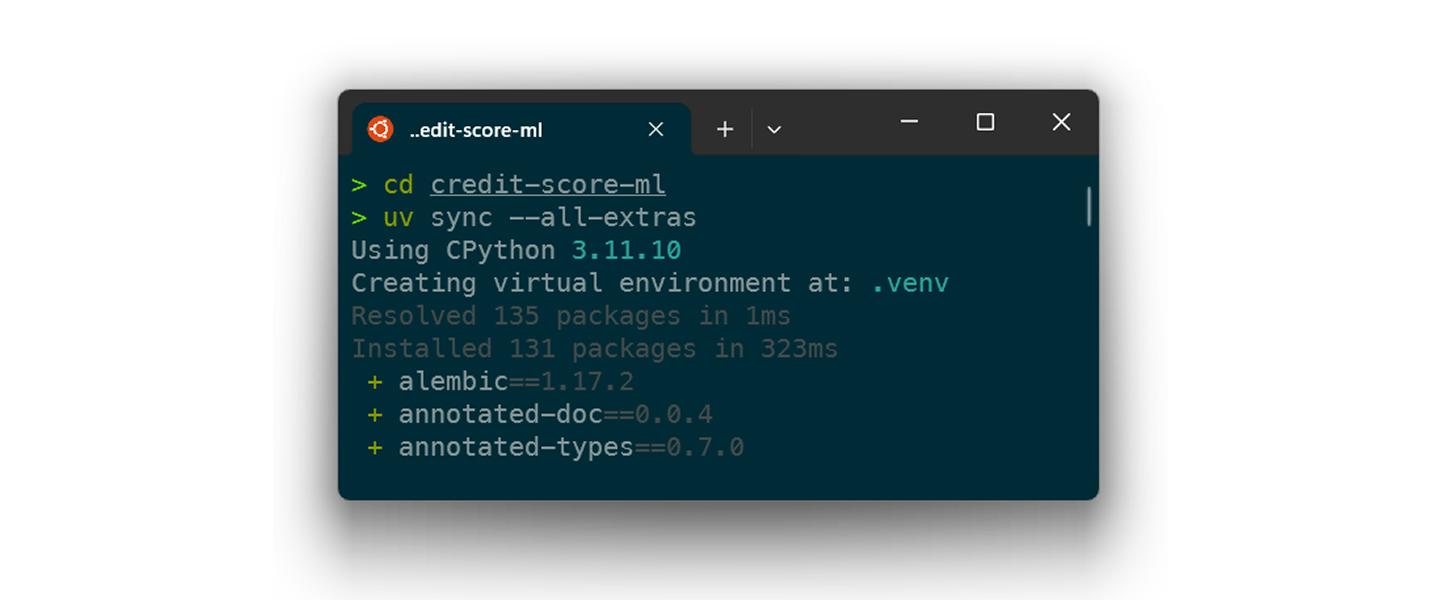 Geschwindigkeit ist kein Luxus, sondern Voraussetzung für Developer Experience. Mit uv eliminieren wir die Wartezeiten im Loop
Geschwindigkeit ist kein Luxus, sondern Voraussetzung für Developer Experience. Mit uv eliminieren wir die Wartezeiten im Loop
Deep Dive 2: Die Supply Chain – Modell als OCI-Artefakt
Hier trennt sich oft die Spreu vom Weizen. In vielen Setups werden Modelle als .pkl- oder .onnx-Dateien auf einen S3 Bucket hochgeladen. Das funktioniert, ist aber schwer zu versionieren und auditieren.
Der moderne Ansatz für 2026: das Modell als OCI-Artefakt.
Kurz zur Einordnung: OCI steht für Open Container Initiative. Das ist das Gremium, das Standards für Container-Formate festlegt (das, was wir umgangssprachlich oft einfach «Docker-Image» nennen). Der Clou ist: OCI-Registries (wie Harbor, Artifactory oder AWS ECR) können heute nicht mehr nur ausführbare Container-Images speichern, sondern beliebige Artefakte.
Wir nutzen diesen Standard, um das Modell inklusive Metadaten in genau denselben «Karton» zu verpacken wie unsere Software. Der Vorteil? Wir brauchen keine separate «Model Registry»-Infrastruktur mehr. Die Tools, die wir für Security-Scanning, Replikation und Access Control für Docker-Images nutzen, funktionieren plötzlich auch für unsere ML-Modelle.
Wir verpacken also nicht nur den Serving-Code, sondern das Modell selbst in dieses Format.
Der Build-Prozess in der Pipeline
Sobald ein Pull Request gemerged wird, startet die CI-Pipeline. Sie tut Folgendes:
1. Linting & Testing: Code-Qualität und Unit-Tests
2. Training-Smoke-Test: ein kurzer Lauf, um sicherzustellen, dass der Code nicht abstürzt
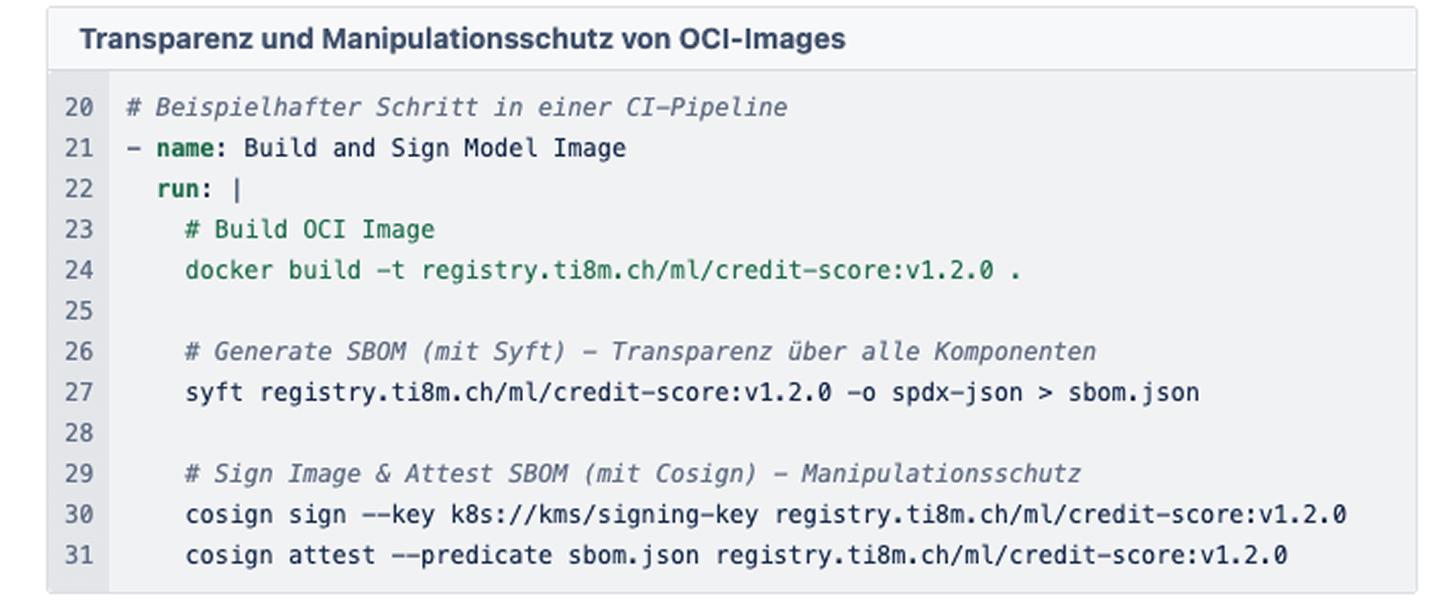
3. Packaging & Signing: Das ist der entscheidende Schritt für die Cybersecurity-Anforderungen (vgl. EU AI Act, Art. 15).
Wir generieren eine SBOM (Software Bill of Materials). Diese Liste enthält alle Python-Pakete, OS-Bibliotheken und Modell-Metadaten. Danach signieren wir den Container kryptografisch (z. B. mit cosign).
Deep Dive 3: Deployment mit GitOps und KServe
Warum dieser Aufwand? Weil der Security Officer im Kubernetes-Cluster nun eine Policy erzwingen kann: «Lasse nur Container starten, die von der CI-Pipeline signiert wurden.» Das schützt vor Supply-Chain-Attacken und stellt sicher, dass kein ungetestetes Modell «aus Versehen» live geht.
Das Modell liegt sicher in der Registry. Wie kommt es live? Hier greift das GitOps-Prinzip. Wir nutzen Argo CD, um den Zustand unseres Clusters zu synchronisieren.
Der Data Scientist (oder die Pipeline) aktualisiert nicht den Cluster direkt. Stattdessen wird ein Commit im gitops-repo gemacht. Das ist unser Audit Trail. Wir können Jahre später noch sagen: «Am 14. Januar 2026 um 14:03 Uhr wurde Modell V2 ausgerollt.»
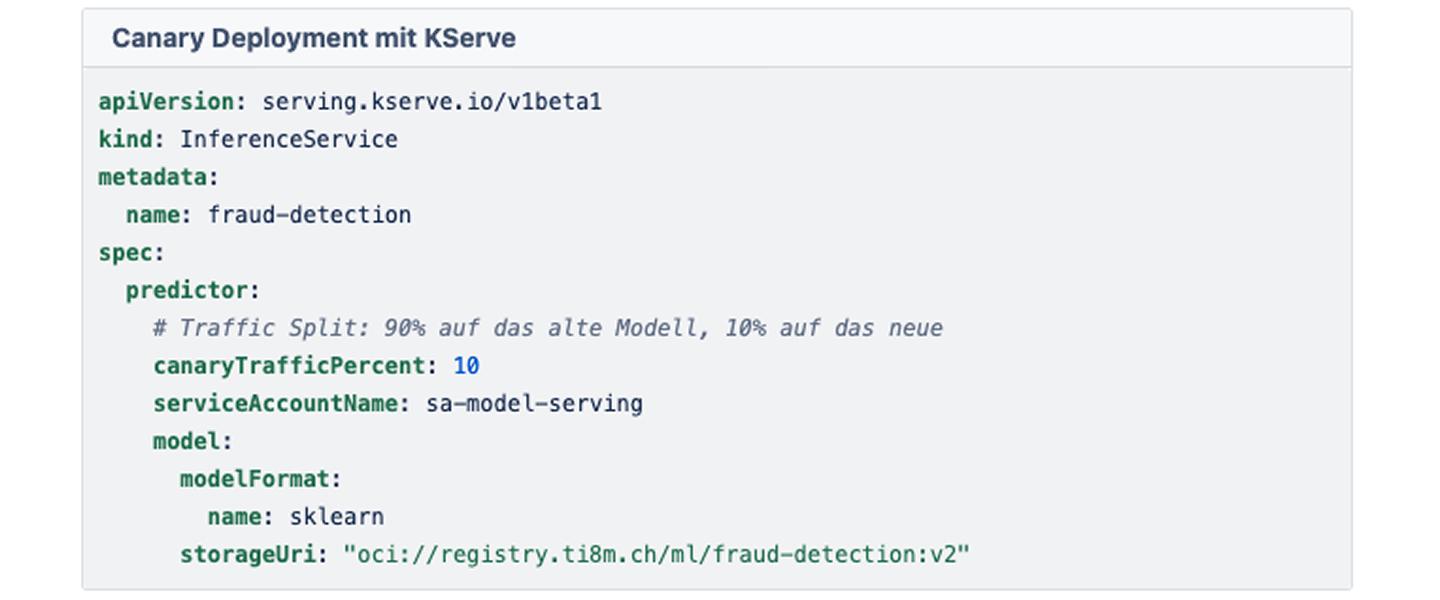
Für das Serving setzen wir auf KServe. KServe abstrahiert die Komplexität von Kubernetes und bietet uns Features wie Scale-to-Zero und Canary Rollouts.
Ein typisches Szenario für ein kritisches Modell-Update:
Wir wollen Modell V2 nicht sofort auf 100 % der User loslassen. Wir nutzen ein «Canary Deployment».
Deep Dive 4: Observability – Mehr als nur «Pod läuft»
Ein laufender Pod bedeutet im ML-Kontext noch lange nicht, dass das System gesund ist. Ein Modell kann technisch perfekt laufen, aber fachlich völligen Unsinn produzieren, weil sich die Eingabedaten verändert haben (Data Drift).
Traditionelles Monitoring (CPU, RAM) reicht hier nicht. Um die Robustheit (vgl. EU AI Act, Art. 15) zu überwachen, brauchen wir semantisches Monitoring.
Wir setzen auf den OpenTelemetry-Standard (OTel-Standard). Unsere Model Server instrumentieren jeden Request. Die Logs und Traces fliessen in einen zentralen Stack (z. B. Loki/Tempo oder Managed Services).
Entscheidend ist, was wir messen:
1. Latenz & Durchsatz: die «Basics»
2. Input-Verteilung: Hat sich das Durchschnittsalter der Kunden im credit-scoring-Modell plötzlich verschoben?
3. Prediction-Verteilung: Lehnt das Modell plötzlich viel mehr Anträge ab als üblich?
Diese Metriken extrahieren wir oft asynchron, um die Latenz der Vorhersage nicht zu beeinträchtigen.
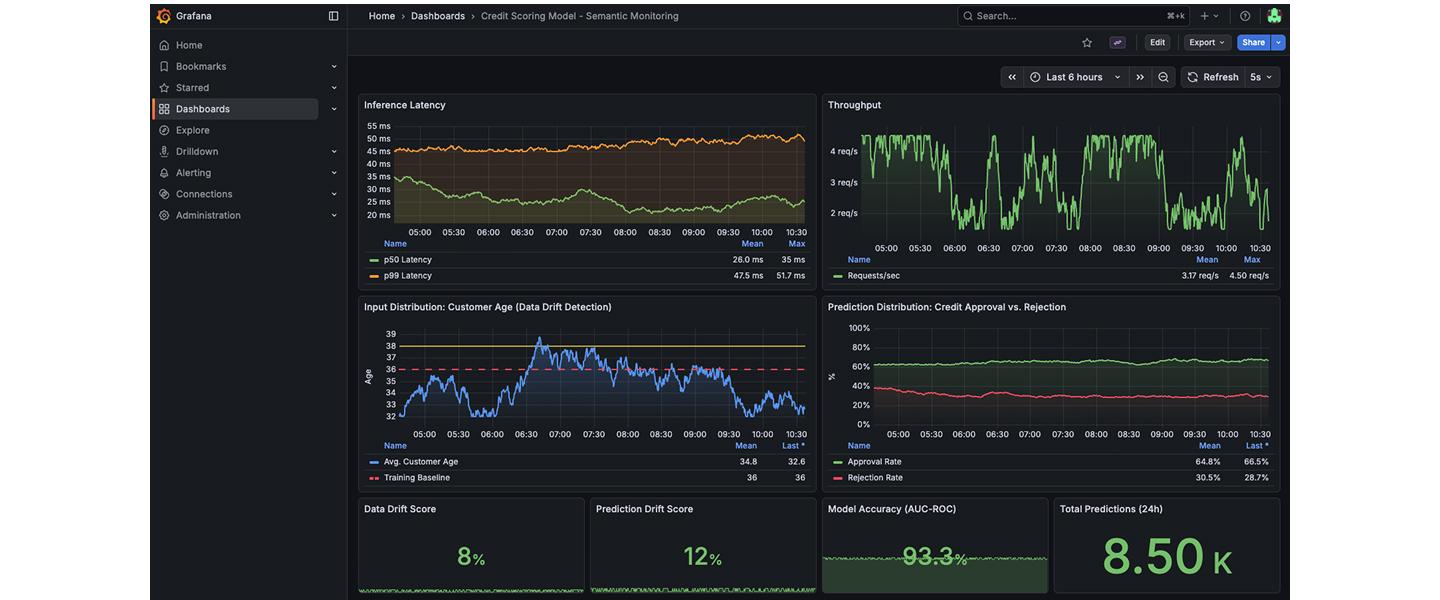 Semantisches Monitoring: Wir alarmieren nicht nur, wenn der Server brennt, sondern auch, wenn das Modell die Realität nicht mehr korrekt abbildet.
Semantisches Monitoring: Wir alarmieren nicht nur, wenn der Server brennt, sondern auch, wenn das Modell die Realität nicht mehr korrekt abbildet.
Fazit: Build vs. Buy? Compose!
Die Frage, ob man eine MLOps-Plattform selbst bauen oder einkaufen soll, ist oft falsch gestellt. Grosse «All-in-One»-Suiten führen häufig zu Vendor-Lock-in und passen selten perfekt auf die spezifischen Compliance-Prozesse eines Schweizer Unternehmens.
Der Ansatz von ti&m ist Compose. Wir nutzen die besten Open-Source-Komponenten der Cloud Native Computing Foundation (CNCF) Landscape – MLflow für die Registry, Argo für GitOps, KServe für Inference, OpenTelemetry für Observability – und integrieren sie zu einem nahtlosen «Golden Path».
Das Resultat ist eine Plattform, die Data Scientists Freiheit gibt (nutzt eure Tools!), aber der IT-Security und dem Risk Management die nötige Kontrolle bietet (alles signiert, alles GitOps, alles auditierbar).
MLOps im Jahr 2026 ist keine Magie mehr. Es ist solides Engineering.
Haben Sie das Gefühl, dass Ihre Data-Science-Projekte immer noch am «Deployment Gap» scheitern? Oder sind Sie unsicher, wie Sie Ihre Modelle fit für kommende Regulierungen machen? Lassen Sie uns darüber sprechen, wie wir Ihren «Golden Path» pflastern können.