



No more “Works on my Machine”: MLOps “Golden Path” blueprint for regulated industries
We are now in 2026. The days when data science teams handed their models over to the IT department on a USB stick or as a ZIP file are finally over. The tooling landscape has undergone huge consolidation in recent years. Today, we’re no longer discussing whether we need containers, but how we can secure the supply chain of our AI models so that they not only perform well, but also meet the rising governance requirements.
Nevertheless, we often see a paradox in our projects at ti&m: While algorithms are becoming increasingly complex (transformers, agentic workflows), the engineering is lagging behind. Notebooks are “hacked” in production, or pipelines - so fragile that nobody dares touch the requirements.txt - are built.
For companies that see ML not as a playground, but as a business-critical driver, there’s only one solution: platform engineering. We need to build a “Golden Path” – a standardized, highly automated road to production.
In this article, we show what a blueprint such as the one we’re currently designing for customers in regulated industries (banks, insurance companies) might look like. We look under the hood of GitOps, OCI artefacts, modern dependency management with uv, and observability.
The mindset: Compliance by design and Swiss pragmatism
Before we look at the code, a word about the architecture. In a regulated environment, “agility” is not a license for chaos.
The issue of regulation – think EU AI Act – is also of central importance for Swiss companies. Although we’re politically independent, our economies are heavily intertwined. As soon as a Swiss company offers AI services in the EU, extraterritorial regulations apply. Swiss legislators are also guided by international standards.
For us technicians, the crucial factor is not so much the legal text, but the technical implications. Two aspects in particular are relevant for MLOps platforms:
Technical documentation & record keeping (Art. 11 & 12): We must be able to provide complete proof of how a model was created. Who trained it? On what data? With which parameters?
Accuracy, robustness & cybersecurity (Art. 15): A model must be non-manipulable and protected against attacks.
Manual steps are the enemy here, so our goal at ti&m is to build a platform where compliance is the automatic result, not a form that you fill out at the end.
Our architecture principles for 2026:
1. GitOps first: The single source of truth is always Git. This guarantees a complete history (audit trail).
2. Immutable artifacts: A model is a binary artifact built once and then promoted unchanged through the stages (Dev, Test, Prod).
3. Separation of concerns: Data scientists provide the content (code + parameters), the platform provides the framework (security, scaling, monitoring).
Deep Dive 1: Reproducibility begins locally (the uv revolution)
Let’s take a brief look back. Dependency management in Python has long been a nightmare. pip, poetry, conda, pipenv – it often took minutes to resolve dependencies.
In 2025, uv established itself as the de facto standard and, in 2026, is indispensable in modern stacks. Why is this crucial for MLOps? Because governance stands and falls with reproducibility.
When a data scientist develops a model locally, the environment must correspond bit for bit to the training environment in the cloud. In the past, “Works on my Machine” led to hours of troubleshooting in the CI pipeline.
With uv, we can create and synchronize environments in milliseconds.
How this looks in practice:
Instead of a loose requirements.txt, we use strict lock files (uv.lock) that work across platforms.
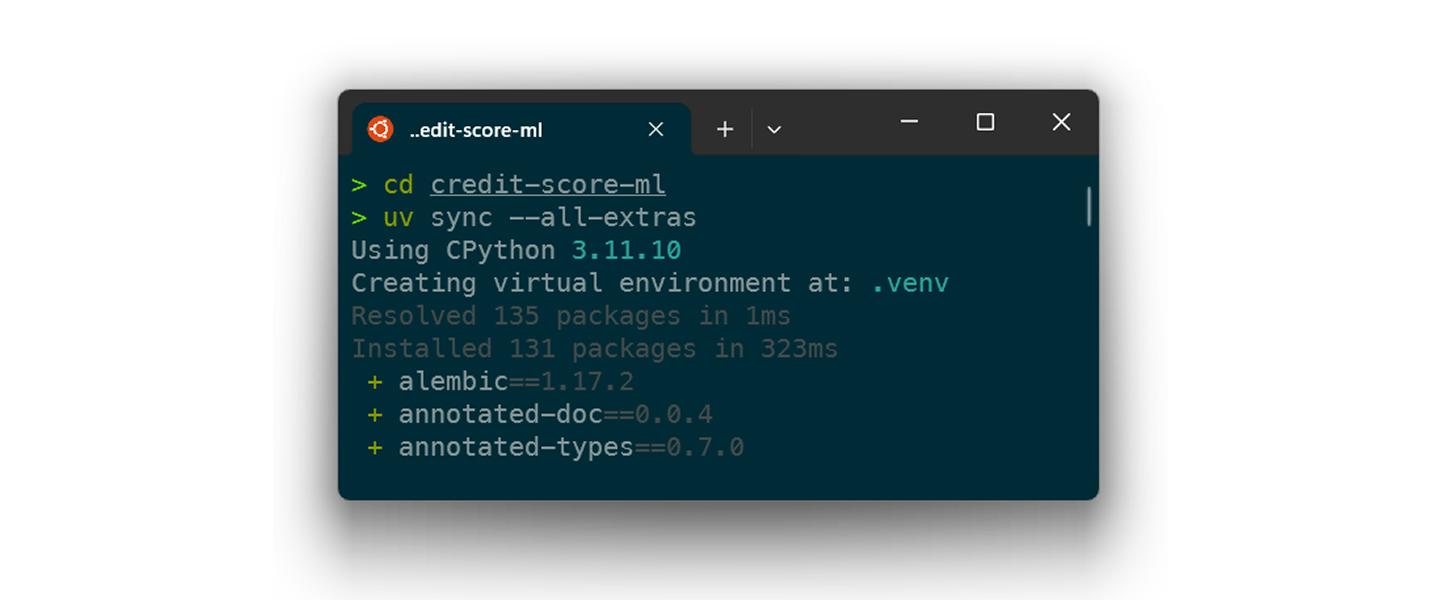 Speed is not a luxury, but a prerequisite for developer experience. With uv, we eliminate the wait times in the loop.
Speed is not a luxury, but a prerequisite for developer experience. With uv, we eliminate the wait times in the loop.
Deep Dive 2: The supply chain model as an OCI artifact
This is often where the wheat is separated from the chaff. In many setups, models are uploaded to an S3 bucket as .pkl or .onnx files. This works, but is difficult to version and audit.
The modern approach for 2026 is the model as an OCI artifact.
A brief note about classification: OCI stands for Open Container Initiative. This is the body that sets standards for container formats (what we often simply call a “Docker image”). The key point is that OCI registries (such as Harbor, Artifactory and AWS ECR) can now store not just executable container images, but any artifacts.
We use this standard to pack the model, including metadata, into exactly the same “box” as our software. The benefit? We don’t need a separate “model registry” infrastructure anymore. The tools we use for security scanning, replication and access control for Docker images suddenly work for our ML models too.
So we pack not only the serving code but also the model itself into this format.
The build process in the pipeline
The CI pipeline starts as soon as a pull request is merged. It does the following:
1. Linting & testing: Code quality and unit tests.
2. Training smoke test: A short run to ensure that the code doesn’t crash.
3. Packaging & signing: This is the crucial step for the cybersecurity requirements (see Art. 15 of the AI Act).
We generate an SBOM (Software Bill of Materials). This list contains all Python packages, OS libraries, and model metadata. We then sign the container cryptographically (e.g. with cosign).
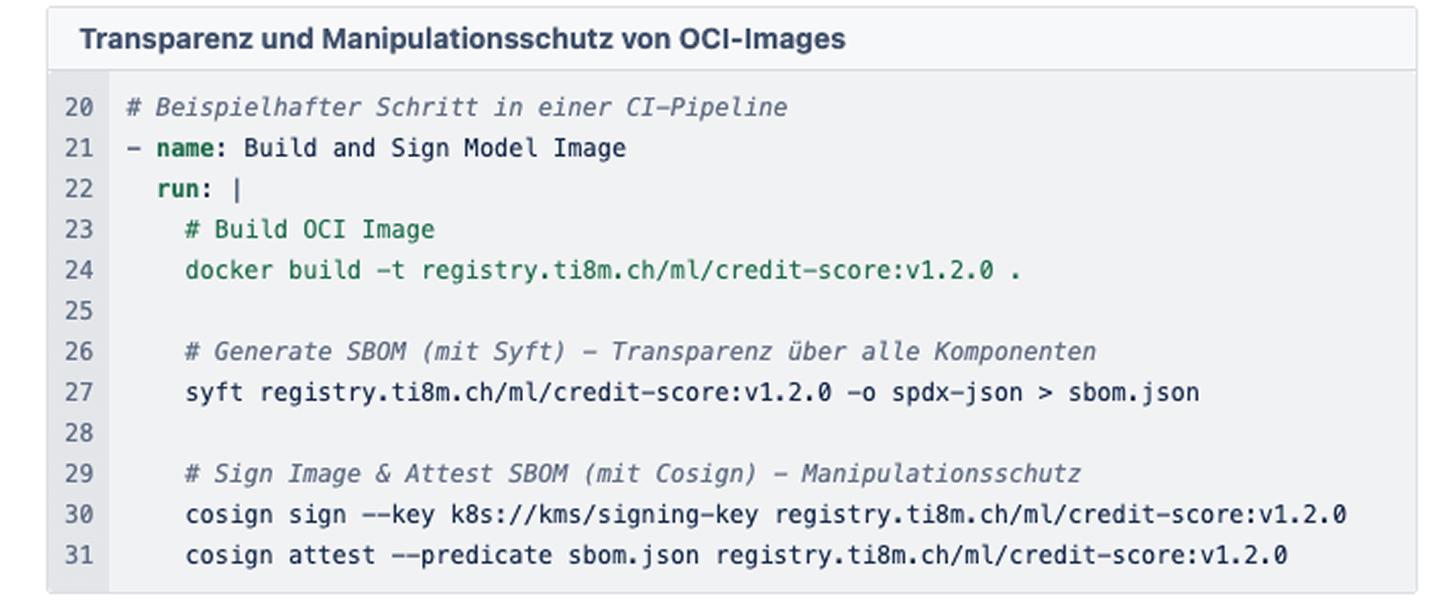 Why all this effort? Because the security officer in the Kubernetes cluster can now enforce a policy: “Only start containers that have been signed by the CI pipeline.” This protects against supply chain attacks and ensures that no untested model goes live “by mistake”.
Why all this effort? Because the security officer in the Kubernetes cluster can now enforce a policy: “Only start containers that have been signed by the CI pipeline.” This protects against supply chain attacks and ensures that no untested model goes live “by mistake”.
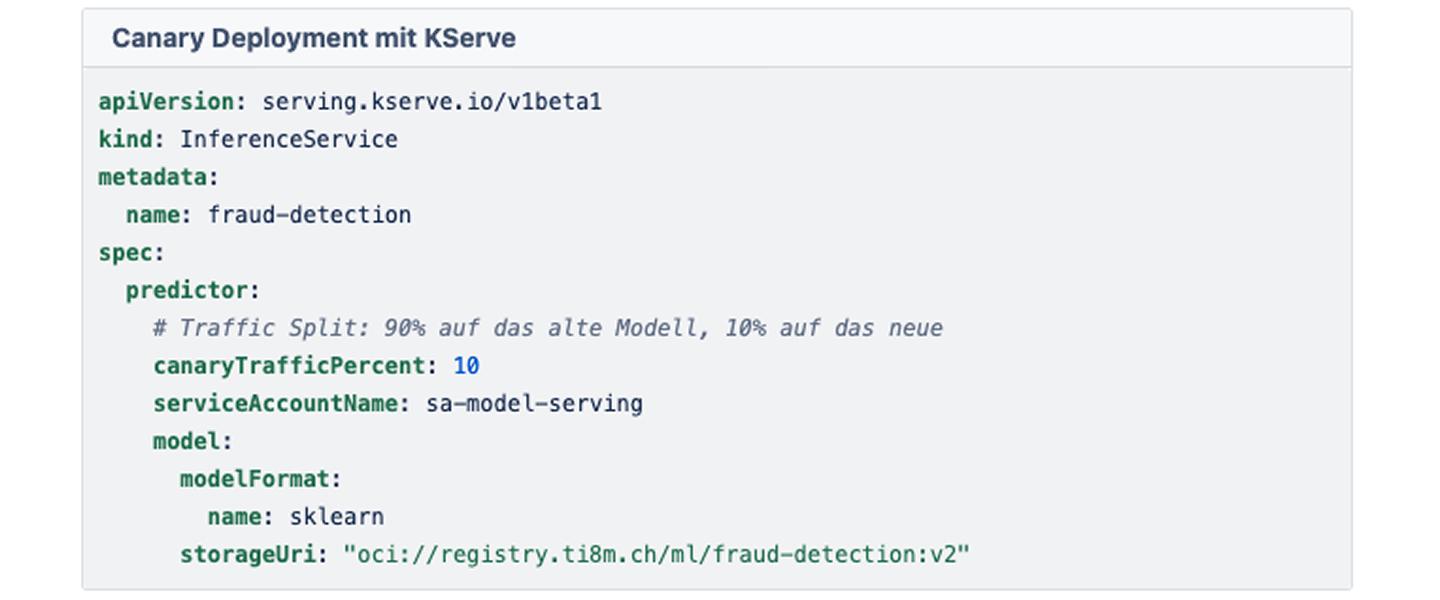
Deep Dive 3: Deployment with GitOps and KServe
The model is safely stored in the registry. How does it go live? This is where the GitOps principle takes effect. We use Argo CD to synchronize the status of our cluster.
The data scientist (or the pipeline) doesn’t update the cluster directly, but a commit is made in the gitops-repo instead. This is our audit trail. Years later, we’ll still be able to say: “Model V2 was rolled out at 14:03 on January 14, 2026.”
For serving, we rely on KServe. It abstracts the complexity of Kubernetes and offers us features such as scale-to-zero and canary rollouts.
A typical scenario for a critical model update might be:
We don’t want to let Model V2 loose on all of our users at once. Let’s use a “canary deployment”.
Deep Dive 4: Observability – more than just “pod running”
In the ML context, a running pod doesn’t necessarily mean that the system is healthy. After all, a model can run perfectly from a technical point of view, but produce complete nonsense because the input data has changed (data drift).
Traditional monitoring (CPU, RAM) is not enough here. To monitor robustness (Art. 15), we need semantic monitoring.
We rely on the OpenTelemetry (OTel) standard. Our model servers instrument every request. The logs and traces flow into a central stack (e.g. Loki/Tempo or Managed Services).
Decisive is what we measure:
1. Latency & throughput: The “basics”.
2. Input distribution: Has the average age of customers in the credit-scoring model suddenly shifted?
3. Prediction distribution: Is the model suddenly rejecting a lot more applications than usual?
We often extract these metrics asynchronously to avoid interfering with the latency of the prediction.
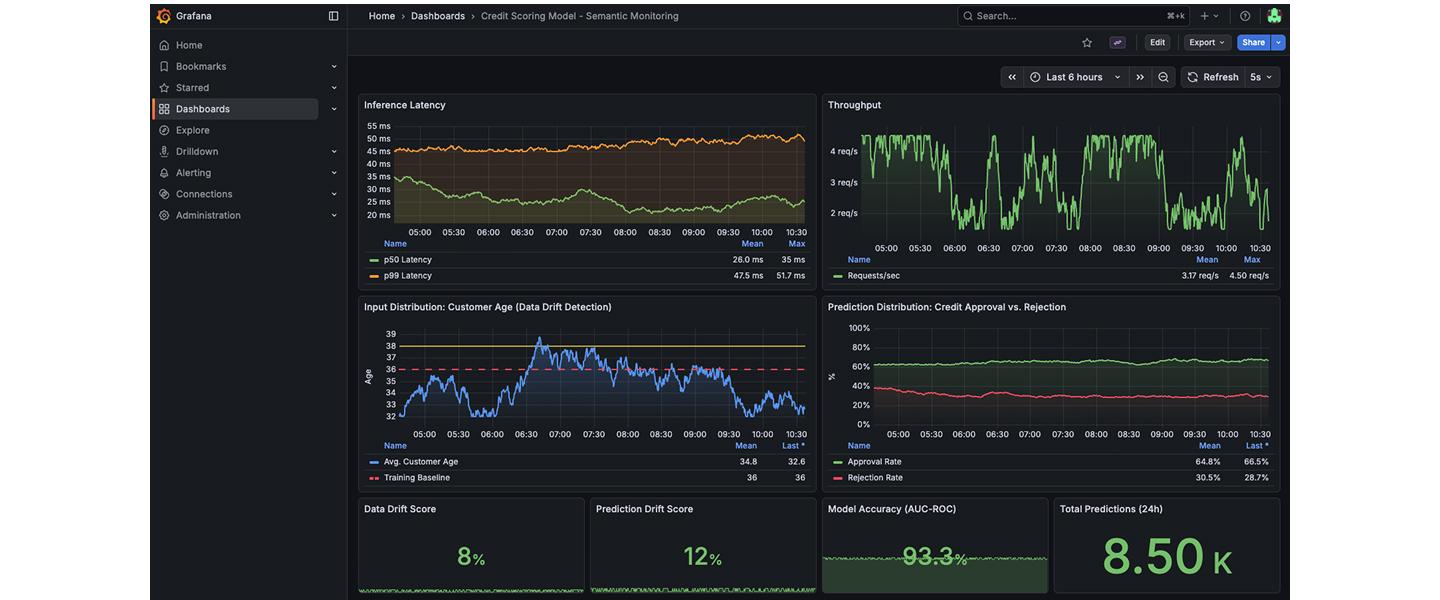 Semantic monitoring: We don’t just raise the alarm when the server is on fire, but also when the model no longer accurately reflects reality.
Semantic monitoring: We don’t just raise the alarm when the server is on fire, but also when the model no longer accurately reflects reality.
The bottom line: Build vs. buy? Compose!
The question of whether to build an MLOps platform yourself or buy one is often misguided. Large “all-in-one” suites often lead to vendor lock-in and are rarely a perfect fit for the specific compliance processes of a Swiss company.
The ti&m approach is to compose. We use the best open-source components of the Cloud Native Computing Foundation (CNCF) landscape – MLflow for the registry, Argo for GitOps, KServe for Inference, OpenTelemetry for Observability – and integrate them into a seamless “Golden Path”.
The result is a platform that gives data scientists freedom (use your tools!), but provides IT security and risk management departments with the necessary control (everything signed, everything GitOps, everything auditable).
In 2026, MLOps isn’t magic anymore, it’s solid engineering.
Do you get the feeling that your data science projects are still failing because of the “deployment gap”? Or are you unsure how to make your models fit for future regulations? Then let’s talk about how we can pave your “Golden Path”.