
Transcribe Swiss German with AI meeting agent
Our Meeting Agent supports every phase of a meeting. Thanks to its intelligent features and cognitive capabilities, your employees are always perfectly prepared and receive reliable summaries and clear to-dos after every customer interaction.
Tailored AI Agents built on industry know-how
For many years we have been developing AI solutions based on ti&m’s expertise and our customers’ requirements. With our AI agents, assistants, and training courses, we offer tailored solutions that ensure effective and scalable applications for thousands of people.
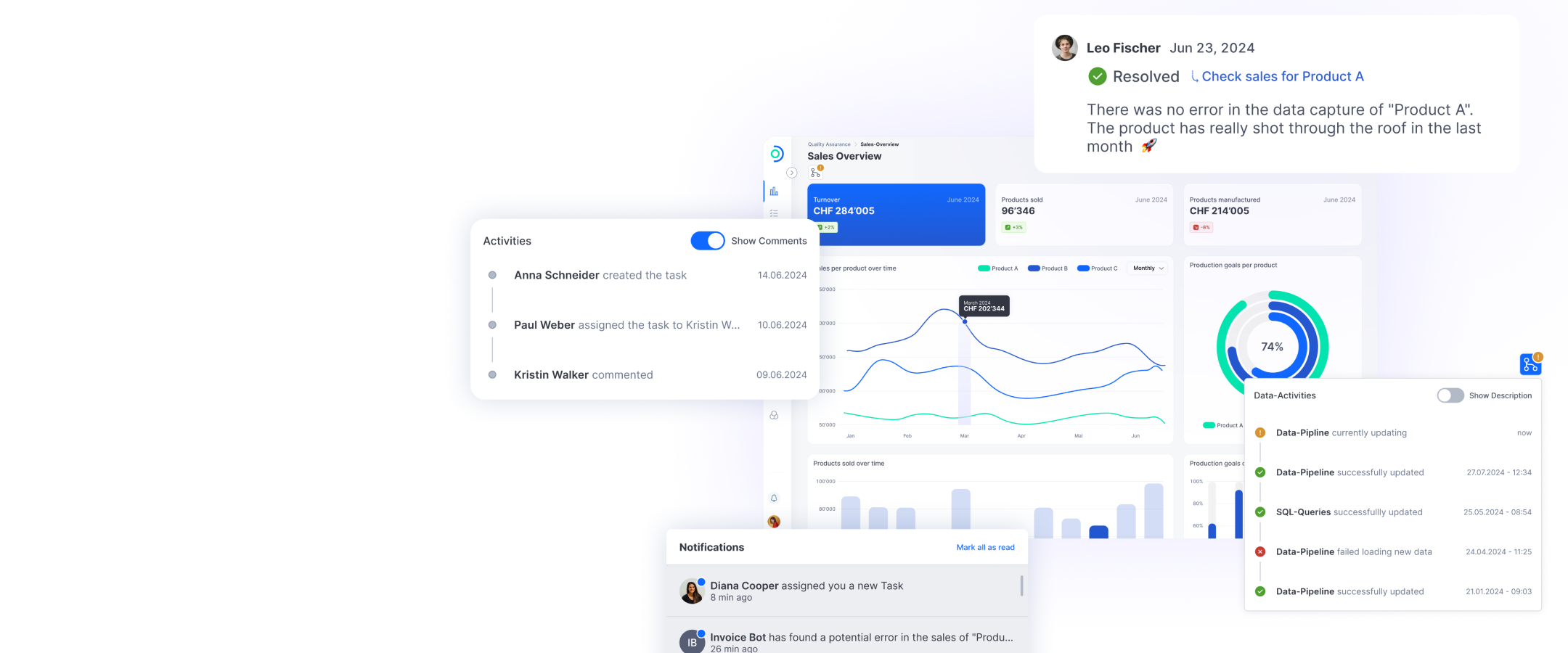
Open Datastack: Simplify complexity, empower collaborative BI
Open Datastack is a modular data platform that is based on open source components and is used both in the cloud and on-premises. The focus of Open Datastack is on interactive collaboration around data, dashboards and workflows.
Tailored AI Agents built on industry know-how
For many years we have been developing AI solutions based on ti&m’s expertise and our customers’ requirements. With our AI agents, assistants, and training courses, we offer tailored solutions that ensure effective and scalable applications for thousands of people.

Bilanz innovation ranking: ti&m among the top innovators
The Innovation Ranking 2025 ranks ti&m among the most innovative companies in Switzerland: ti&m is among the top 10 in the categories ‘Top 150 innovators in Switzerland’ and ‘Innovation culture’.

We are one of the best employers in Switzerland 2025
In a comprehensive study, the Handelszeitung together with Statista identified the best employers in Switzerland in 2025. We are proud to have secured third place in the "Internet, Telecommunications and IT" sector.
How to protect your organization from AI-driven identity fraud
White paper ”Fighting AI-driven Identity Fraud“ | Artificial intelligence is transforming business processes — but it’s also creating new opportunities for fraud. Deepfakes, synthetic identities, and automated attacks are on the rise at an alarming rate.