



S&P Global
Sustainability assessments with AI
Assessment of the sustainability of companies' practices and business models
S&P has the world’s largest database of assessments of the sustainability of companies’ practices and business models. Over 10,000 companies around the world are assessed each year.
This is done on the one hand by issuing industry-specific questionnaires with structured and unstructured questions, which is the most productive aspect of this method. Company reports and publicly available information are also compiled and analyzed on a regular basis.
Our solutions

Machine-Learning
ti&m has trained a range of machine learning models, which are now capable of comparing businesses' statements and responses with company reports and other sources. These models undertake repetitive tasks for analysts and significantly reduce the time needed to complete assessments.

PoC
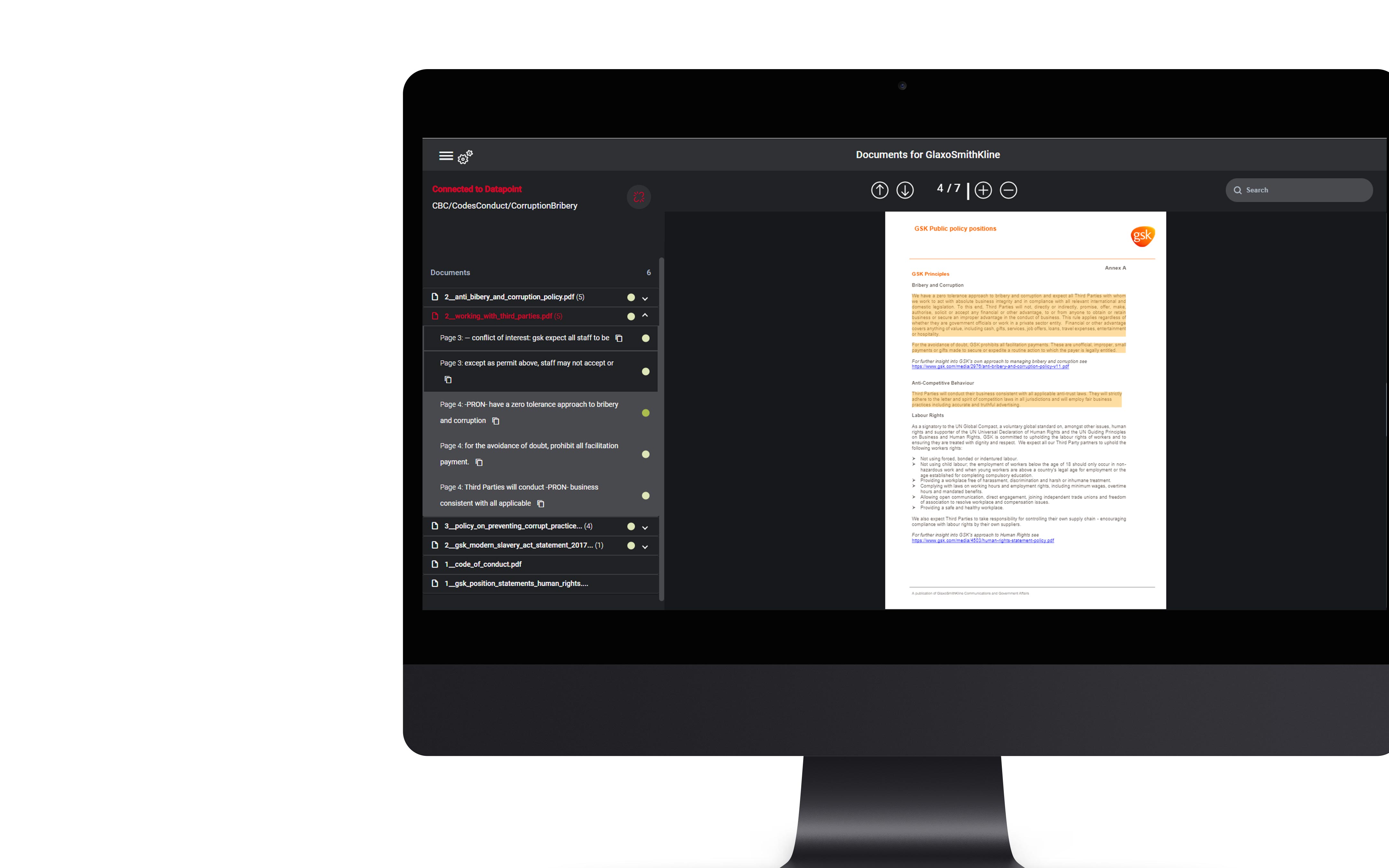
for two specific types of questions: Finding relevant information in documents and evaluating responses from the “Material Issues” category, such as “Executive Compensation”.

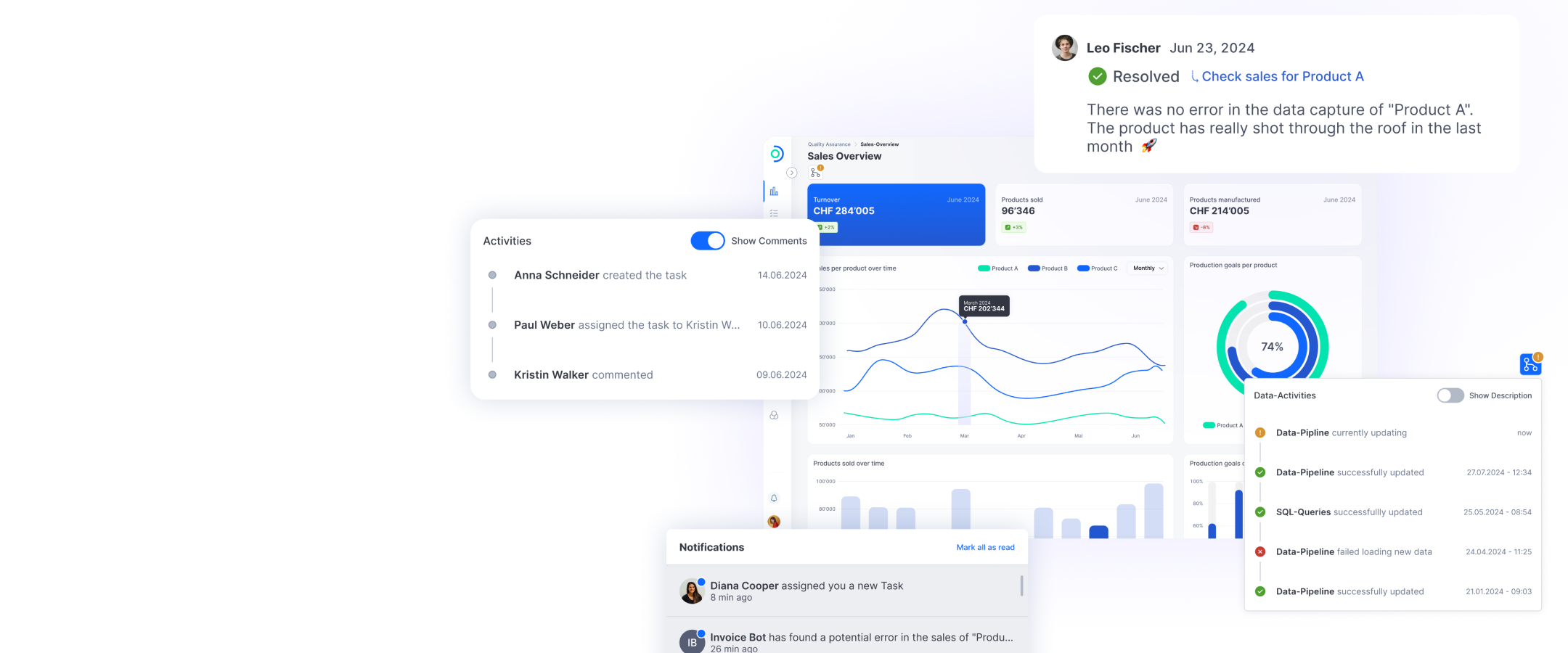
Front-end / Back-end
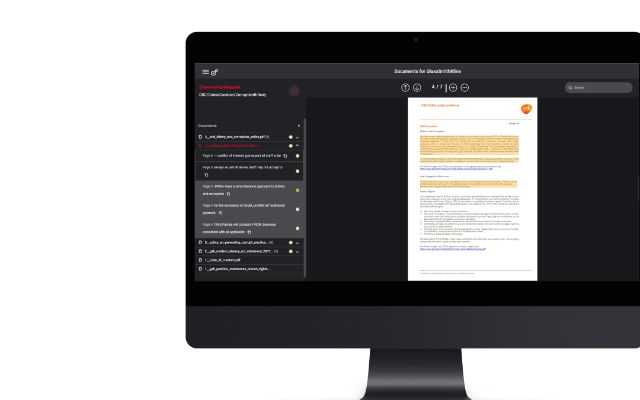
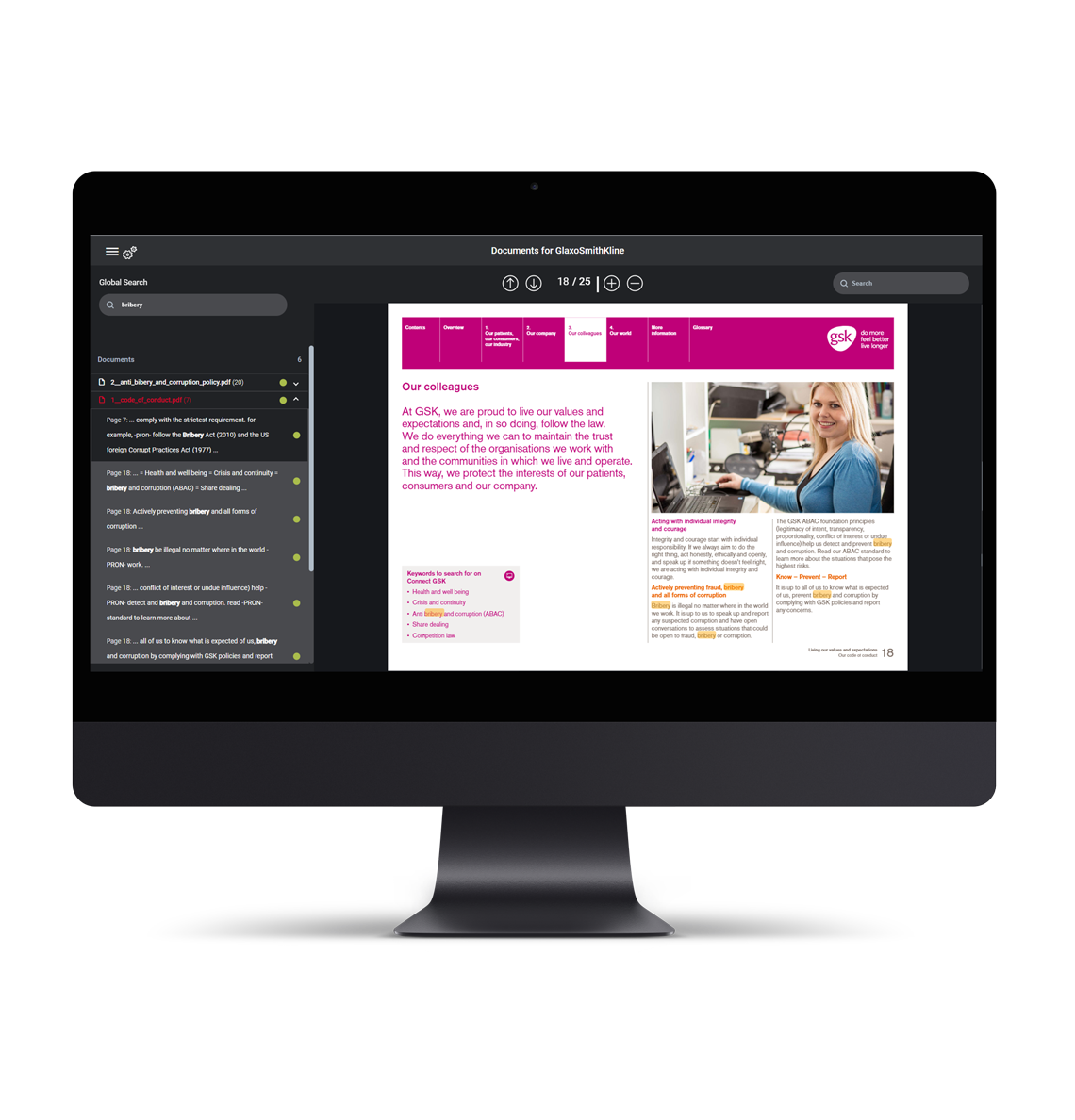
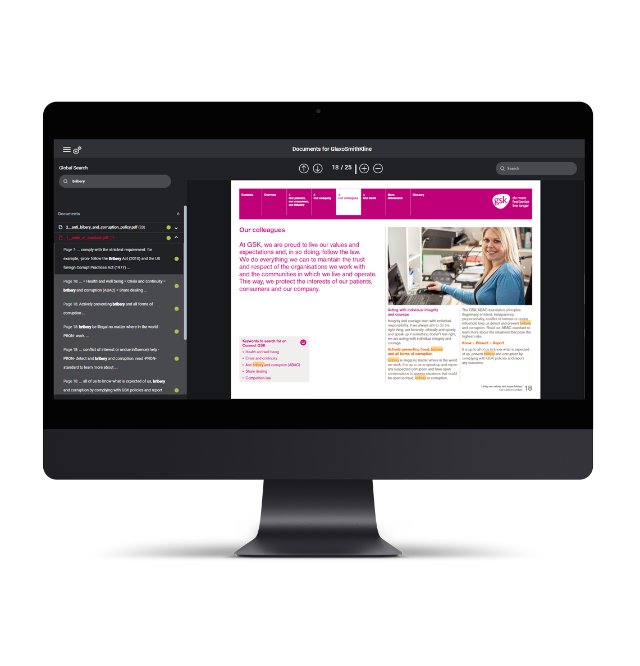
solution for visualizing documents, incl. displaying the relevant text passages for different categories.

Globale Search
of all relevant documents referring to the company to be assessed.

Data Processing Pipeline & Integration
for extracting text from documents into the existing S&P application using OCR.
Management of machine learning models
to create and train new models for specific categories.

Technical implementation
of software as microservice architecture


Challenges
01
Training NLP models
for the specific domain without excessive data volumes.
02
Data
The process first had to be adjusted so as to enable the analysts to generate structured data that could then serve as the ground truth for the models.
03
Approaches
The many different question types (documents/quantitative responses/timelines/free text) mean that different models and approaches are required.
04
Priority
Prioritization was based on the time-saving potential for each question type.

Collaboration
The project was launched in collaboration with the Corporate Sustainability Assessment (CSA) department of RobecoSAM (2019), and was later taken over by and integrated into S&P Global (2020/21).
Project implementation
61
Sectors
10000
Companies
170000
Documents
2,4
Million Data Points

Head of AI & Digital Solutions
Lisa Kondratieva
We have the right experts for all AI related matters! We would be delighted to advise you on all aspects of the topic.