


Event sourcing: Storing events instead of discarding data
Event sourcing // Modern software technologies need to meet more and more complex business requirements. Effective concepts are needed to handle data efficiently. The traditional approach of storing state-based data is reaching its limits. Event sourcing fundamentally changes this.
To illustrate this, let’s take the simple example of a company that holds data about its employees. During the recruitment process, the company initially collects data such as ID, fi rst name, last name, role and department. This information changes over time, such as when the employee is promoted or moves to a new department. When something changes, the corresponding dataset is usually updated to refl ect the current state. This works well for simple requirements.
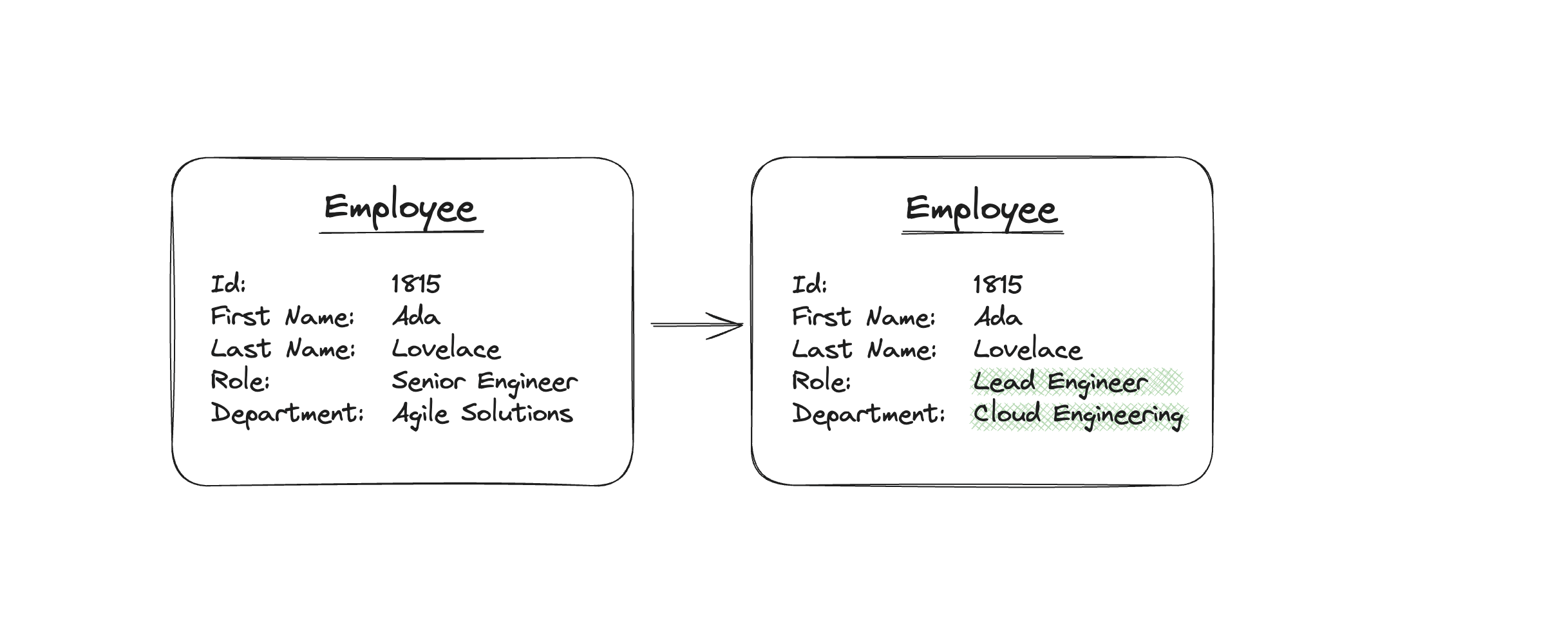 Changes to a dataset mean we lose the previous information.
Changes to a dataset mean we lose the previous information.
However, sometimes employees might be promoted several times or switch departments. If the dataset is updated, the old information is lost, even though it may still be useful for various purposes. But there are ways to retain this information, such as by using a table that logs the changes. Unfortunately this approach is often inadequate since this requirement only arises at a later stage. As a key component of software architecture, event sourcing considers these requirements to be fun- damental. A deeper analysis of our example shows that state changes take place as a result of domain events. If you organize these events by time, you can tell a story about the changes to our data. So as well as being able to see the current state, you can also reconstruct all of the previous states as well. What happens now, when instead of storing the state, we store the events that caused the state to arise?
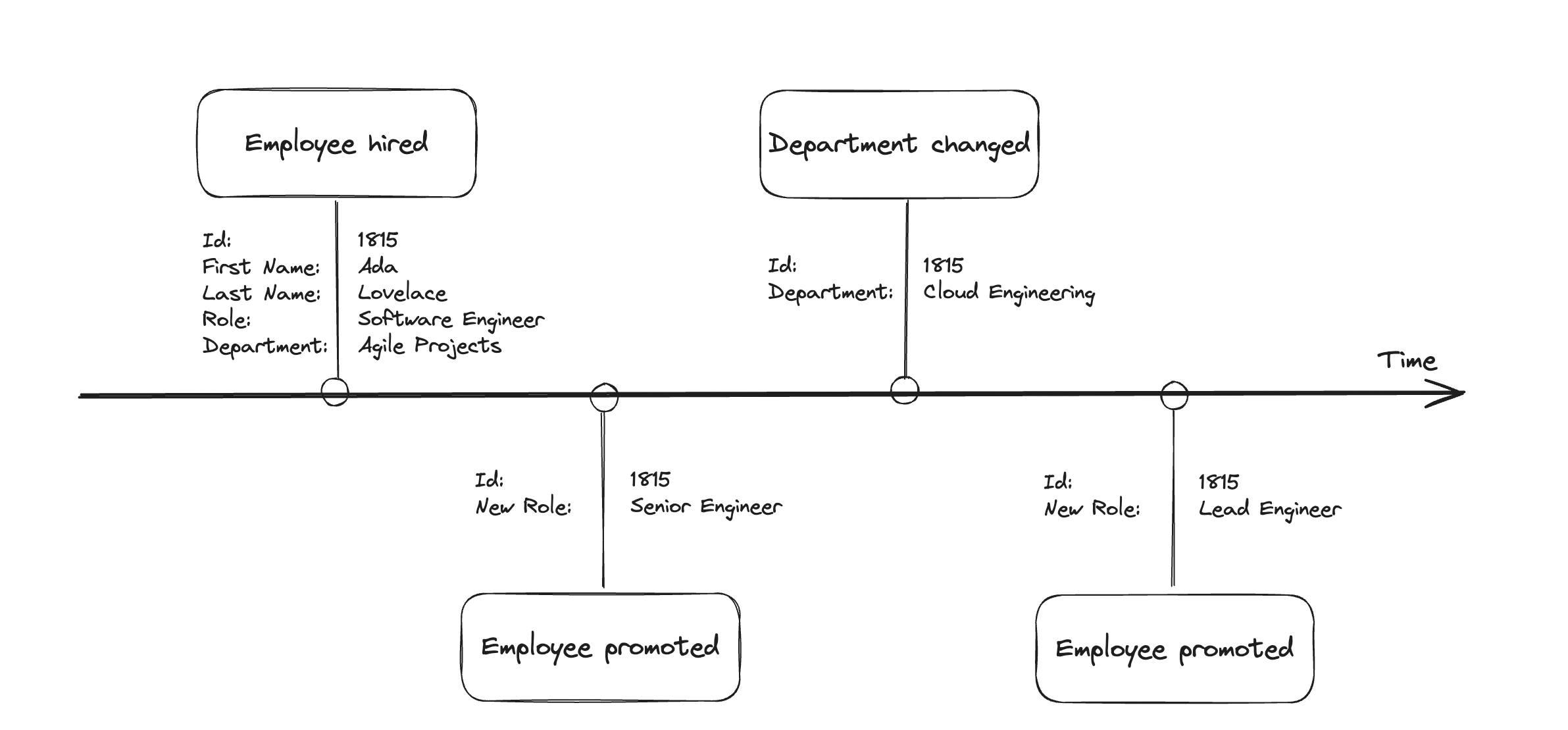 Event-based data storage with event sourcing
Event-based data storage with event sourcing
Event sourcing is a pattern that puts this idea into practice. Related events are added to an event stream. The events are immutable — during the event stream, events can only be added onto the end. An event store is ultimately about the persistency of the event stream. The event store is the primary data source here and represents the single source of truth.
The advantages of event sourcing
1. No data left behind
Since events are only ever added to the end of the stream, no information is overwritten. In our example there were two promotions: Instead of losing data through updates, semantic events were stored. An additional log is not necessary. We can subsequently create a historical list of the employee’s previous roles and departments, and use this to determine all prior events.
2. Data history facilitates comprehensive analysis
The mapping and transparency of the entire history enable us to draw conclusions. This is because the domainspecific meaning of events can provide valuable information: Has the employee’s role changed due to promotion or changes to the company’s role structure? Have they moved departments or changed their name? It also gives us the chance to carry out temporal queries: How long was the gap between two role changes? How many employees switched departments last year?
3. Greater transparency
We can restore a past state at any time, which is of interest for new domain requirements as well as technical error analysis. Through this we gain 100 % transparency, which meets all the requirements of an audit trail and avoids synchronization issues.
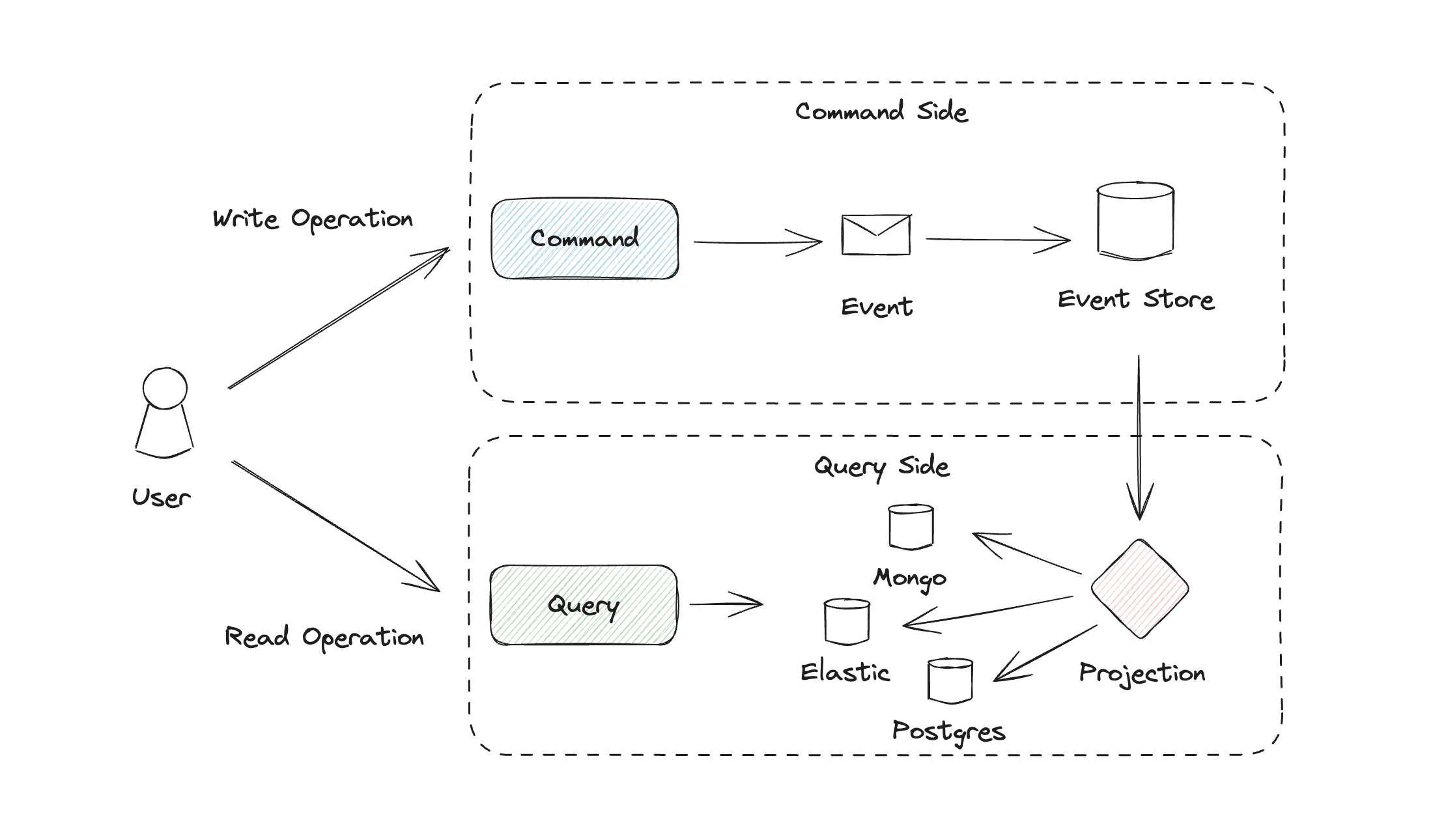 Event sourcing and command query responsibility segregation complement each other
Event sourcing and command query responsibility segregation complement each other
Command query responsibility segregation (CQRS) is a pattern that complements event sourcing.
It separates read and write operations. Write operations are called commands and lead to events which are persisted through event sourcing. Projections translate these events into models optimized for queries. Read operations, on the other hand, are called queries and can effi ciently access these optimized models. These models are created during the projection and can be efficiently queried. Combining event sourcing and CQRS allows for highly scalable systems. You can scale the database of the event store and the projected models individually, as well as the interfaces for commands and queries, and projections. However, event sourcing also has its challenges. The growing number of events also increases the effort needed to run through an event stream. Event stream slicing according to domain requirements, introducing snapshots, and using CQRS are all possible solutions. Changes that are not backward compatible require event streams to be migrated. And fi nally, you should not underestimate the learning curve it presents for your team. Thanks to event sourcing, we are no longer discarding data. Event sourcing has proven itself to be a powerful and flexible approach to managing complex requirements. It enables us to develop sustainable, scalable and complex software systems that not only satisfy current demands, but are also equipped for future challenges.


Special, AI
Establishing a data and analytics organization
Data management // The exponential growth of data volumes, legal requirements, and increasing demands on cybersecurity due to more sophisticated attacks require a comprehensive data strategy that covers all bases. By setting up a data and analytics organization, companies can create a structure that takes all relevant data capabilities into account.
David Furrer - Apr 10, 2024
Digital Banking, Special
From identification to authentication: Our products for digital trust
Philip Dieringer - May 2, 2025
Special, Digital Banking
Swiss digitalization solutions for the Singapore Financial Center
Singapore // With innovative solutions, our nearly 20 employees in Singapore are driving the digitalization of the financial industry in Asia. The shakeout in fintech and the crypto market should now be used by established banks to expand their wealth management with new, customer-friendly solutions.
Marc Bühler - May 24, 2023