



Special, AI
The future of blockchain interoperability
Web 3.0 // Blockchains play a key role in the ongoing development and decentralization of the internet. With “the interchain”, the Interchain Foundation in Zug is establishing an ecosystem that simplifies interoperability between individual chains through standards, thus driving the development of Web 3.0.
Mary McGilvary - Apr 1, 2024
Special, AI
Cyber risk mitigation — increasing costs or creating value?
Cybersecurity // Protecting critical data, systems and processes affects core elements of a company’s value creation chain, and is directly linked to the firm’s success. Company management teams must manage these cyber risks and be proactive in staying aware of the associated responsibilities.
Andreas Berger - Mar 20, 2024
Future of Work
The Benefit of AI in Desk Booking
AI and desk booking // In the aftermath of the global pandemic, the traditional office landscape has undergone a profound transformation. As remote working became the new norm, demand for desk booking systems initially decreased. However, as organizations begin to navigate the complexities of hybrid work models, the need for flexible and efficient workspace management solutions has reached new heights. We show how AI can help.
Andri Bühler - Mar 9, 2024
Special, AI
“AI is playing an increasingly important role in the music industry”
New technologies in rights management // SUISA ensures that composers and lyricists receive royalties for the use of their works. In this interview, Overall IT Manager, Jürg Ziebold, explains the key AI applications for this.
Jürg Ziebold - Mar 5, 2024
Future of Work
Maximizing collaboration and productivity: The value of Teams Apps for hybrid work
Hybrid work // In the rapidly evolving landscape of hybrid work, communication and collaboration are essential. Beyond its well-known standard features like chats, video meetings and calls, Microsoft Teams has more to offer. Teams has emerged as a leading platform, offering a comprehensive suite of tools seamlessly integrated with Microsoft 365 applications. This integration makes it the preferred hub for collaboration in the modern workplace.
Andri Bühler - Feb 29, 2024
Special, AI
Data-driven banking: Mission data – leveraging coporate treasures
Data-driven banking // Data strategies are becoming increasingly relevant. As the basis for new projects, innovative solutions and the development of new business models, business alignment, data governance and data management lay the foundation for exploiting the opportunities created by new technologies.
Fabian Braunwalder - Feb 14, 2024
Special, AI
Financial industry in transition: Time to say goodbye to account — card — credit pack
Digital ecosystems // Technologically transparent business model design is high on the strategic agenda of financial services providers. But many are struggling with the challenges of this new breed of competition. To succeed, businesses need to find new value propositions, learn co-innovation and retain control in a changed industry.
Joachim Stonig - Feb 7, 2024
Special, AI
Event sourcing: Storing events instead of discarding data
Event sourcing // Modern software technologies need to meet more and more complex business requirements. Effective concepts are needed to handle data efficiently. The traditional approach of storing state-based data is reaching its limits. Event sourcing fundamentally changes this.
André Fröhlich - Jan 30, 2024
Special, AI
“Digital ethics: In some contexts, we shouldn’t use autonomous systems at all”
Digital ethics // Oliver Bendel has been researching and publishing books on information, robot and machine ethics for many years, and has been invited to speak as an expert at the German Bundestag and European Parliament several times. We talked to him about the opportunities associated with AI, the morals behind the machines, plus the concepts of guilt and responsibility with autonomous systems.
Oliver Bendel - Jan 19, 2024
Special, AI
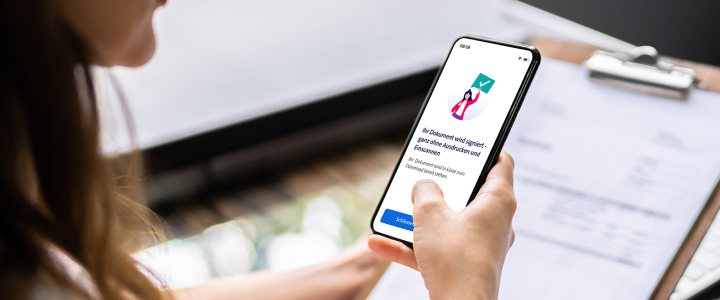
Using your smartphone as a pen
Swisscom Sign // Since last fall, people through-out Switzerland have been able to sign contracts electronically using the My Swisscom app. The function is available to everyone, regardless of whether they are a Swisscom customer or not.
Andreas Tölke - Jan 10, 2024
Special, AI
How to use AI to make the most of company data
AI assistants // Intelligent chatbots like the ti&m AI Assistants combine company data with the intelligence of ChatGPT or Google Bard. This gives companies a chatbot that can support employees with many different tasks, and simplify and improve customer communication.
Ursin Brunner - Jan 8, 2024
Special, AI
Language-based productivity — artificial intelligence as a copilot
Microsoft Switzerland // ChatGPT brings AI into the realm of human language, opening up new possibilities and sparking debates. The real added value is much less disruptive than you might think, as it in fact boosts productivity and satisfaction.
Marc Holitscher - Jan 5, 2024